SG.hu·
Archiválás DNS-ben
Az ötlet nem új, a DNS alapvetően eddig is információt tárolt a genomok formájában, az Európai Bioinformatikai Intézet (EBI) kutatói azonban megpróbálták saját igényeik szerint működésre bírni.
Az adatok mennyisége gyorsabban nő, mint a tárolásukhoz használt merevlemezek kapacitása, különösen igaz ez az EBI genetikai adatállományára. "Ez azt jelenti, hogy a tárolás költségei emelkednek, miközben saját költségvetésünk stagnál" - magyarázta Dr. Nick Goldman, az EBI munkatársa, aki kollégájával, Ewan Birney-vel azon elmélkedett, vajon a mesterségesen előállított DNS megoldást jelenthet-e a természetes DNS-einkből származó adatáradat tárolására. A párosnak sikerült kidolgozni egy működőképesnek tűnő sémát, majd némi módosítgatás és egy sikeres próba után a Nature szaklapban publikálták eredményeiket.
Goldman megoldása több tekintetben is figyelemre méltó. Csapatával rekord mennyiségű, 739,3 kilobájt egyedi információt sikerült kódolnia, a rendszert azonban ennél sokkal nagyobb mennyiségre tervezték. A kutatók szerint könnyedén elnyelheti azt a körülbelül 3 zettabájt (egy zettabájt 1021 bájt) digitális adatot, ami jelenleg a világon létezik, és még bőven marad hely további adatmennyiség tárolására is. Mindezt közel 2,2 petabájt (1015) grammonkénti sűrűséggel oldják meg, így a világ teljes digitális információhalmaza felférne egy teherautó platójára. Mindezek mellett az új módszer drasztikusan csökkenti az eddigi DNS adattárolás másolási hibáit, az archivált anyag pedig évezredeken át fennmaradhat a DNS-ben, ellentétben a mágneses adathordozókkal.
A módszer hatékonysága abban a megoldásban rejlik, amivel a kutatók átalakítják fájljaikat a merevlemezekről. A DNS négy kémiai bázist használ - adenint (A), timint (T) citozint (C) és guanint (G) - az információ kódolásához. A korábbi kísérletek általában közvetlenül próbálták átalakítani a bináris adattárolás egyeseit és nulláit ezekbe a bázisokba, így például az A ás C jelentette a nullát, míg a G és T az egyet. A bázisok ismétlődése azonban hibás visszaolvasásokat eredményezett.
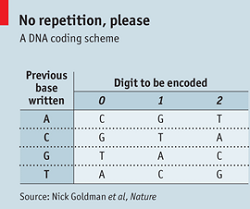 A csapat a bináris számítógépes információkat hármas számrendszerbe alakítja (0,1 és 2), és ezután kódolja az adatokat a DNS-be. Az adott szám és az adott bázis közvetlen kapcsolata helyett a kódolási séma azon múlik, hogy melyik bázist használták legutoljára (lásd a képen). Például ha az előző bázis A volt, akkor egy kettest a T fog megtestesíteni, azonban ha az előző bázis G volt, akkor a kettest a C képviseli. A behelyettesítési szabály biztosítja, hogy egy azonos számokból álló sorozat az adatokban ne a DNS azonos bázisainak szekvenciájában jelenjenek meg, így kiküszöböli a hibákat.
A csapat a bináris számítógépes információkat hármas számrendszerbe alakítja (0,1 és 2), és ezután kódolja az adatokat a DNS-be. Az adott szám és az adott bázis közvetlen kapcsolata helyett a kódolási séma azon múlik, hogy melyik bázist használták legutoljára (lásd a képen). Például ha az előző bázis A volt, akkor egy kettest a T fog megtestesíteni, azonban ha az előző bázis G volt, akkor a kettest a C képviseli. A behelyettesítési szabály biztosítja, hogy egy azonos számokból álló sorozat az adatokban ne a DNS azonos bázisainak szekvenciájában jelenjenek meg, így kiküszöböli a hibákat.
A kódot ezután mesterséges DNS-be táplálják. A legegyszerűbb megoldás egy-egy hosszú DNS szál szintetizálása lenne minden tárolandó fájl számára. A DNS szintetizáló gépek azonban még nem képesek erre, ezért a kutatók úgy döntöttek, hogy fájljaikat több ezer különálló részre darabolják, melyek mindegyike 117 bázis hosszúságú. Ezekben a darabokban 100 bázis áll magának a tárolandó adatnak a rendelkezésére, a maradékot pedig az indexelésre fordítják, ami megmondja hová tartozik az adott darab a teljes állományban. A folyamat magába foglalja a hibajelző "paritásbit" DNS megfelelőjét is.
A még nagyobb hibatűrés érdekében a kutatók úgy alkották meg a darabokat, hogy némi átfedés legyen közöttük, ezáltal egy 100 bázisos darab 25 bázisa a DNS három másik darabjában is jelen van, tehát ha bármilyen másolási hiba jelentkezik egy adott darabban, akkor összehasonlítható három másolatával és a többség elve alapján eldönthető, melyik a helyes. A darabok visszaolvasása egy szabványos kémiai reakcióval megoldható egy DNS-szekvenáló gépben.
 A tesztelésnél a módszer majdnem terv szerint működött. A kutatóknak sikerült öt számítógép fájlt be- és kikódolniuk, köztük Martin Luther King beszédének egy MP3-ba kódolt részletét, valamint Francis Crick és James Watson 1953-ban a DNS szerkezetéről publikált írásának PDF változatát. Az összes elővigyázatosság ellenére azonban két 25 bázisos DNS szegmens eltűnt a PDF fájl esetében. A problémát részben a DNS kémiájának, részben a szintézist végző gépeknek tulajdonítják. Goldman biztos benne, hogy a kódolás finomra hangolásával a jövőben elkerülhetővé válik ez a probléma.
A tesztelésnél a módszer majdnem terv szerint működött. A kutatóknak sikerült öt számítógép fájlt be- és kikódolniuk, köztük Martin Luther King beszédének egy MP3-ba kódolt részletét, valamint Francis Crick és James Watson 1953-ban a DNS szerkezetéről publikált írásának PDF változatát. Az összes elővigyázatosság ellenére azonban két 25 bázisos DNS szegmens eltűnt a PDF fájl esetében. A problémát részben a DNS kémiájának, részben a szintézist végző gépeknek tulajdonítják. Goldman biztos benne, hogy a kódolás finomra hangolásával a jövőben elkerülhetővé válik ez a probléma.
Az DNS-ben történő adattárolásnak mindenesetre vannak hátulütői is. Az egyik az adatok visszaolvasásának viszonylag lassú sebessége. A kutatóknak két hetükbe került az öt fájl rekonstruálása, bár jobb felszereléssel állításuk szerint mindez egy nap alatt megoldható. Valljuk be, ez sem túl biztató, bár több szekvenáló géppel a folyamat felgyorsítható lenne. Az egész kutatás iróniája, hogy a módszer pont arra a célra nem alkalmazható, amire az EBI-nek szüksége lenne, a hatalmas genom adatmennyiség interneten való elérhetővé tételére, ugyanakkor kevésbé gyakran használt archívumoknál ez nem jelentene problémát. Ilyen lehetne a CERN, ami hatalmas archívummal rendelkezik a különböző részecskefizikai kísérletek adataiból.
Nem beszéltünk még a költségekről, melyek szintén nem túl biztatóak a módszer jelenlegi állapotában. Goldman becslései szerint megoldásukkal egy megabájt tárolása körülbelül 12.400 dollárba kerülne, ami több milliószorosa ugyanennyi adatmennyiség mágneses szalagra írásának. Azt sem szabad ugyanakkor elfelejteni, hogy a mágneses szalagokat néhány év elteltével cserélni kell, míg a DNS évezredeken át olvasható marad, amennyiben megfelelő hőmérsékleten, naptól védett száraz helyen tárolják, ezért minél hosszabb távra szól egy adott adathalmaz tárolása, annál vonzóbbá válhat a DNS. Mindemellett a DNS szintetizálás költségei is igen gyors ütemben csökkennek, a kutatók szerint egy évtizeden belül versenyképessé válhatnak a ritkán használt archívumoknál alkalmazott módszerekkel szemben.

Van még egy nagyon fontos előnye a DNS-nek. A modern digitális tárolási technológiák jönnek és mennek, vegyük csak a lézer lemez példáját. A 2000-es évek elején a NASA kénytelen volt végigböngészni az internetes árveréseket, hogy hozzájusson néhány ódivatú nyolccolos floppy meghajtóhoz az 1960-as - '70-es évek adatainak visszanyeréséhez, míg a DNS több mint 3 milliárd éve létezik, így amíg létezik az élet - és a biológusok - addig valaki mindig lesz, aki olvasni tudja majd a DNS-ben tárolt adatokat.
Az adatok mennyisége gyorsabban nő, mint a tárolásukhoz használt merevlemezek kapacitása, különösen igaz ez az EBI genetikai adatállományára. "Ez azt jelenti, hogy a tárolás költségei emelkednek, miközben saját költségvetésünk stagnál" - magyarázta Dr. Nick Goldman, az EBI munkatársa, aki kollégájával, Ewan Birney-vel azon elmélkedett, vajon a mesterségesen előállított DNS megoldást jelenthet-e a természetes DNS-einkből származó adatáradat tárolására. A párosnak sikerült kidolgozni egy működőképesnek tűnő sémát, majd némi módosítgatás és egy sikeres próba után a Nature szaklapban publikálták eredményeiket.
Goldman megoldása több tekintetben is figyelemre méltó. Csapatával rekord mennyiségű, 739,3 kilobájt egyedi információt sikerült kódolnia, a rendszert azonban ennél sokkal nagyobb mennyiségre tervezték. A kutatók szerint könnyedén elnyelheti azt a körülbelül 3 zettabájt (egy zettabájt 1021 bájt) digitális adatot, ami jelenleg a világon létezik, és még bőven marad hely további adatmennyiség tárolására is. Mindezt közel 2,2 petabájt (1015) grammonkénti sűrűséggel oldják meg, így a világ teljes digitális információhalmaza felférne egy teherautó platójára. Mindezek mellett az új módszer drasztikusan csökkenti az eddigi DNS adattárolás másolási hibáit, az archivált anyag pedig évezredeken át fennmaradhat a DNS-ben, ellentétben a mágneses adathordozókkal.
A módszer hatékonysága abban a megoldásban rejlik, amivel a kutatók átalakítják fájljaikat a merevlemezekről. A DNS négy kémiai bázist használ - adenint (A), timint (T) citozint (C) és guanint (G) - az információ kódolásához. A korábbi kísérletek általában közvetlenül próbálták átalakítani a bináris adattárolás egyeseit és nulláit ezekbe a bázisokba, így például az A ás C jelentette a nullát, míg a G és T az egyet. A bázisok ismétlődése azonban hibás visszaolvasásokat eredményezett.
A csapat a bináris számítógépes információkat hármas számrendszerbe alakítja (0,1 és 2), és ezután kódolja az adatokat a DNS-be. Az adott szám és az adott bázis közvetlen kapcsolata helyett a kódolási séma azon múlik, hogy melyik bázist használták legutoljára (lásd a képen). Például ha az előző bázis A volt, akkor egy kettest a T fog megtestesíteni, azonban ha az előző bázis G volt, akkor a kettest a C képviseli. A behelyettesítési szabály biztosítja, hogy egy azonos számokból álló sorozat az adatokban ne a DNS azonos bázisainak szekvenciájában jelenjenek meg, így kiküszöböli a hibákat.A kódot ezután mesterséges DNS-be táplálják. A legegyszerűbb megoldás egy-egy hosszú DNS szál szintetizálása lenne minden tárolandó fájl számára. A DNS szintetizáló gépek azonban még nem képesek erre, ezért a kutatók úgy döntöttek, hogy fájljaikat több ezer különálló részre darabolják, melyek mindegyike 117 bázis hosszúságú. Ezekben a darabokban 100 bázis áll magának a tárolandó adatnak a rendelkezésére, a maradékot pedig az indexelésre fordítják, ami megmondja hová tartozik az adott darab a teljes állományban. A folyamat magába foglalja a hibajelző "paritásbit" DNS megfelelőjét is.
A még nagyobb hibatűrés érdekében a kutatók úgy alkották meg a darabokat, hogy némi átfedés legyen közöttük, ezáltal egy 100 bázisos darab 25 bázisa a DNS három másik darabjában is jelen van, tehát ha bármilyen másolási hiba jelentkezik egy adott darabban, akkor összehasonlítható három másolatával és a többség elve alapján eldönthető, melyik a helyes. A darabok visszaolvasása egy szabványos kémiai reakcióval megoldható egy DNS-szekvenáló gépben.
A tesztelésnél a módszer majdnem terv szerint működött. A kutatóknak sikerült öt számítógép fájlt be- és kikódolniuk, köztük Martin Luther King beszédének egy MP3-ba kódolt részletét, valamint Francis Crick és James Watson 1953-ban a DNS szerkezetéről publikált írásának PDF változatát. Az összes elővigyázatosság ellenére azonban két 25 bázisos DNS szegmens eltűnt a PDF fájl esetében. A problémát részben a DNS kémiájának, részben a szintézist végző gépeknek tulajdonítják. Goldman biztos benne, hogy a kódolás finomra hangolásával a jövőben elkerülhetővé válik ez a probléma. Az DNS-ben történő adattárolásnak mindenesetre vannak hátulütői is. Az egyik az adatok visszaolvasásának viszonylag lassú sebessége. A kutatóknak két hetükbe került az öt fájl rekonstruálása, bár jobb felszereléssel állításuk szerint mindez egy nap alatt megoldható. Valljuk be, ez sem túl biztató, bár több szekvenáló géppel a folyamat felgyorsítható lenne. Az egész kutatás iróniája, hogy a módszer pont arra a célra nem alkalmazható, amire az EBI-nek szüksége lenne, a hatalmas genom adatmennyiség interneten való elérhetővé tételére, ugyanakkor kevésbé gyakran használt archívumoknál ez nem jelentene problémát. Ilyen lehetne a CERN, ami hatalmas archívummal rendelkezik a különböző részecskefizikai kísérletek adataiból.
Nem beszéltünk még a költségekről, melyek szintén nem túl biztatóak a módszer jelenlegi állapotában. Goldman becslései szerint megoldásukkal egy megabájt tárolása körülbelül 12.400 dollárba kerülne, ami több milliószorosa ugyanennyi adatmennyiség mágneses szalagra írásának. Azt sem szabad ugyanakkor elfelejteni, hogy a mágneses szalagokat néhány év elteltével cserélni kell, míg a DNS évezredeken át olvasható marad, amennyiben megfelelő hőmérsékleten, naptól védett száraz helyen tárolják, ezért minél hosszabb távra szól egy adott adathalmaz tárolása, annál vonzóbbá válhat a DNS. Mindemellett a DNS szintetizálás költségei is igen gyors ütemben csökkennek, a kutatók szerint egy évtizeden belül versenyképessé válhatnak a ritkán használt archívumoknál alkalmazott módszerekkel szemben.
Van még egy nagyon fontos előnye a DNS-nek. A modern digitális tárolási technológiák jönnek és mennek, vegyük csak a lézer lemez példáját. A 2000-es évek elején a NASA kénytelen volt végigböngészni az internetes árveréseket, hogy hozzájusson néhány ódivatú nyolccolos floppy meghajtóhoz az 1960-as - '70-es évek adatainak visszanyeréséhez, míg a DNS több mint 3 milliárd éve létezik, így amíg létezik az élet - és a biológusok - addig valaki mindig lesz, aki olvasni tudja majd a DNS-ben tárolt adatokat.