Gyurkity Péter
Socket G34 - foglalatóriás az AMD-től
A friss útiterv szerint az AMD 2010-ben vált ismét foglalatot, a Socket G34 néven érkező fejlesztés pedig a második generációs 45 nanométeres, DDR3 memóriával kiegészülő Opteron chipek számára nyújt majd otthont.
Ázsiai források a cég saját, most kiszivárgott friss útitervére hivatkozva számoltak be az új foglalat fejlesztéséről. A Socket G34 a szerverekbe szánt Opteron chipek számára készül, megjelenése az évtized végén várható, amikor is az AMD teljes erővel a DDR3 memória támogatása felé fordul majd. Igazi erőművek készülnek a vállalat háza táján, csak legyen elég türelmünk (és nekik elég pénzük) a megjelenéshez.
A témában tájékozottak jól tudják, hogy a cég még mindig adós a 45 nanométeres szerver- és asztali processzorokkal. Ezek Shanghai kódnéven készülnek, megjelenésük pedig még az év vége előtt várható - alapos késéssel a nagy rivális Intelhez képest. Az első generációt azonban viszonylag rövid idő múltán követi majd a második, mégpedig a Sao Paolo kódnevű 8 magos, valamint a Magny-Cours néven készülő 12 magos processzorok képében. Ezek a chipek négyutas HyperTransport 3 technológiával, magonként 512 kB másodszintű, valamint összesen 12 MB harmadszintű gyorsítótárral érkeznek majd, felvéve a versenyt a szintén most készülő Nehalem családdal.
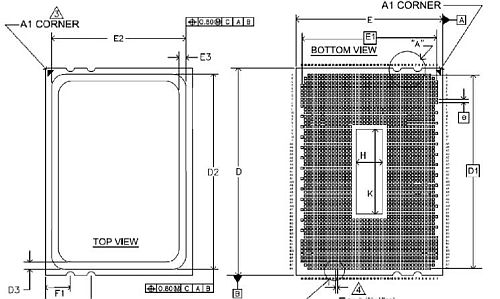
Maga a foglalat meglehetősen összetett, egészen pontosan 1974 lábat tartalmaz, ami jóval több mint a legutoljára piacra dobott LGA1207 érintkezőinek száma. A projekt eredetileg a Socket G3 foglalat kidolgozására indult, ezt azonban idén márciusban dobták, majd megalkották az utódot. A fejlesztés elsőként az RD890S és RD870S jelzésű chipkészletekben kap majd helyet, ezek elkészülte szintén jövő év végére, 2010 elejére várható - a DDR3 támogatás révén a 800 és 1600 MHz közötti példányokat vehetjük majd kezelésbe.
A negyedik HyperTransport link megjelenése találgatásokra ad okot. Tekintettel arra, hogy egy négy foglalatot tartalmazó összeállításban mindegyik chip három linket használ a társaival való kapcsolattartásra, a negyedik (egyes vélemények szerint) a Torrenza projektben meghatározott feladatokat hajthatja majd végre. Ez a Cell chipekkel történő kombinálást hivatott elősegíteni, ami elsősorban a szuperszámítógépek szegmensében jöhet jól a cég számára.
Ázsiai források a cég saját, most kiszivárgott friss útitervére hivatkozva számoltak be az új foglalat fejlesztéséről. A Socket G34 a szerverekbe szánt Opteron chipek számára készül, megjelenése az évtized végén várható, amikor is az AMD teljes erővel a DDR3 memória támogatása felé fordul majd. Igazi erőművek készülnek a vállalat háza táján, csak legyen elég türelmünk (és nekik elég pénzük) a megjelenéshez.
A témában tájékozottak jól tudják, hogy a cég még mindig adós a 45 nanométeres szerver- és asztali processzorokkal. Ezek Shanghai kódnéven készülnek, megjelenésük pedig még az év vége előtt várható - alapos késéssel a nagy rivális Intelhez képest. Az első generációt azonban viszonylag rövid idő múltán követi majd a második, mégpedig a Sao Paolo kódnevű 8 magos, valamint a Magny-Cours néven készülő 12 magos processzorok képében. Ezek a chipek négyutas HyperTransport 3 technológiával, magonként 512 kB másodszintű, valamint összesen 12 MB harmadszintű gyorsítótárral érkeznek majd, felvéve a versenyt a szintén most készülő Nehalem családdal.
Maga a foglalat meglehetősen összetett, egészen pontosan 1974 lábat tartalmaz, ami jóval több mint a legutoljára piacra dobott LGA1207 érintkezőinek száma. A projekt eredetileg a Socket G3 foglalat kidolgozására indult, ezt azonban idén márciusban dobták, majd megalkották az utódot. A fejlesztés elsőként az RD890S és RD870S jelzésű chipkészletekben kap majd helyet, ezek elkészülte szintén jövő év végére, 2010 elejére várható - a DDR3 támogatás révén a 800 és 1600 MHz közötti példányokat vehetjük majd kezelésbe.
A negyedik HyperTransport link megjelenése találgatásokra ad okot. Tekintettel arra, hogy egy négy foglalatot tartalmazó összeállításban mindegyik chip három linket használ a társaival való kapcsolattartásra, a negyedik (egyes vélemények szerint) a Torrenza projektben meghatározott feladatokat hajthatja majd végre. Ez a Cell chipekkel történő kombinálást hivatott elősegíteni, ami elsősorban a szuperszámítógépek szegmensében jöhet jól a cég számára.
