SG.hu·
Szoftver a mesterséges intelligenciák előítéletei ellen

Az IBM programja azt vizsgálja majd, hogy a technológia által hozott döntések előítéletesek-e és ha igen, mennyire.
A mesterséges intelligencia a döntései során hajlamos az előítéletekre, hiszen minden olyan esetben, amikor a gépeket emberek programozták be vagy látták el adatokkal, az előítéletek megjelenhetnek a gépi intelligenciában is. S még a tisztán gépi társadalmak sem lennének teljesen előítéletektől mentesek. Az IBM Research által fejlesztett megoldás automatikusan elemezni fogja a különböző mesterséges intelligencia rendszereket. Ez segíthet abban, hogy meg lehessen találni azt, hogy mik állhatnak az esetleges előítéletes döntések hátterében.
Az új szoftver felismeri az eltérő csoportokon belül az egyes személyek diszkriminálását, továbbá azt is kimutatja, ha több csoport közül egyet másként értékelnek és a mesterséges intelligencia az adott esetben más döntést hoz. Az IBM kutatói számára fontos, hogy felismerjék a befolyásolt eredmények forrásait. Amennyiben kiderül, hogy például negatív tendencia van a színes bőrűekkel szemben, akkor tüzetesen megvizsgálja ezt a célcsoportot. A program akár saját teszthelyzeteket is generálhat, majd azokat átfuttathatja a képzett gépi tanulási modelleken. Az eredményeket megjegyzésekkel és grafikákkal együtt jeleníti meg, hogy így tegye érthetőbbé a vizsgált mesterséges intelligencia döntéseit.
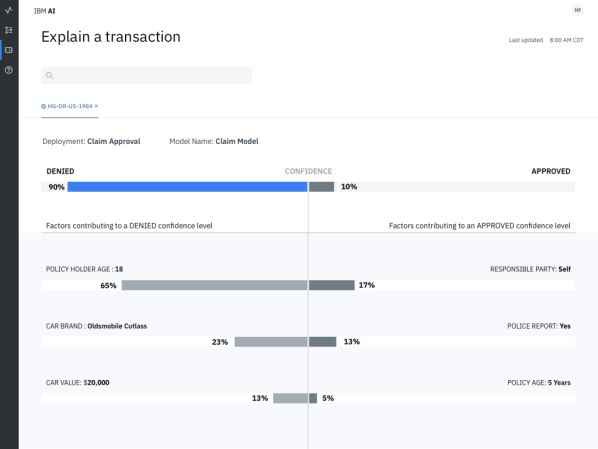
Az IBM megoldása képes feljegyezni és elérhetővé tenni a mesterséges intelligencia rendszerek fejlesztési folyamatait. A szoftver a fejlesztés minden egyes fontos lépését rögzíti, például a forrásadatok gyűjtését, az alkalmazott modellek képzését és a modellgenerálás használatát. Feljegyzi az egyes modellek adatait és a forráskódjait. Ezen információk alapján a program képes egy mesterséges intelligencia döntéshozatalát és az ahhoz használt kritériumokat grafikusan megjeleníteni. Így láthatóvá válik, hogy például egy biztosítási kárigényt miért utasítottak el. Az új megoldás olyan rendszerekkel használható együtt, mint a Watson, a Tensorflow, a SparkML, az AWS SageMaker és az AzureML.
Joy Buolamwini, az MIT Media Lab kutatójaként és az Algorithmic Justice League vezetőjeként a gépi tanuláson alapuló rendszerek előítéletei és sztereotípiái ellen harcol. A tudós kiemelte, hogy kutatásaik szerint a sötét bőrrel rendelkező emberek nincsenek megfelelően reprezentálva azokban az adatbázisokban, amelyekkel az automatikus arcfelismerő szoftvereket képezik. Az algoritmusokat nem tanítják meg megfelelően arra, hogy változatos arcokat ismerjenek fel és ez nagyon pontatlan eredményekhez vezet. Holott nagyon is fontos az, hogy a technológia megfelelően működjön - különösen akkor, ha olyan döntéseket hoz, amelyeknek komoly következményeik lehetnek. Tavaly augusztusban például kiderült, hogy a képfelismerő algoritmusok szexisták: amennyiben egy konyhát látnak, akkor azt automatikusan a nőkkel hozzák kapcsolatba.
A mesterséges intelligencia a döntései során hajlamos az előítéletekre, hiszen minden olyan esetben, amikor a gépeket emberek programozták be vagy látták el adatokkal, az előítéletek megjelenhetnek a gépi intelligenciában is. S még a tisztán gépi társadalmak sem lennének teljesen előítéletektől mentesek. Az IBM Research által fejlesztett megoldás automatikusan elemezni fogja a különböző mesterséges intelligencia rendszereket. Ez segíthet abban, hogy meg lehessen találni azt, hogy mik állhatnak az esetleges előítéletes döntések hátterében.
Az új szoftver felismeri az eltérő csoportokon belül az egyes személyek diszkriminálását, továbbá azt is kimutatja, ha több csoport közül egyet másként értékelnek és a mesterséges intelligencia az adott esetben más döntést hoz. Az IBM kutatói számára fontos, hogy felismerjék a befolyásolt eredmények forrásait. Amennyiben kiderül, hogy például negatív tendencia van a színes bőrűekkel szemben, akkor tüzetesen megvizsgálja ezt a célcsoportot. A program akár saját teszthelyzeteket is generálhat, majd azokat átfuttathatja a képzett gépi tanulási modelleken. Az eredményeket megjegyzésekkel és grafikákkal együtt jeleníti meg, hogy így tegye érthetőbbé a vizsgált mesterséges intelligencia döntéseit.
Az IBM megoldása képes feljegyezni és elérhetővé tenni a mesterséges intelligencia rendszerek fejlesztési folyamatait. A szoftver a fejlesztés minden egyes fontos lépését rögzíti, például a forrásadatok gyűjtését, az alkalmazott modellek képzését és a modellgenerálás használatát. Feljegyzi az egyes modellek adatait és a forráskódjait. Ezen információk alapján a program képes egy mesterséges intelligencia döntéshozatalát és az ahhoz használt kritériumokat grafikusan megjeleníteni. Így láthatóvá válik, hogy például egy biztosítási kárigényt miért utasítottak el. Az új megoldás olyan rendszerekkel használható együtt, mint a Watson, a Tensorflow, a SparkML, az AWS SageMaker és az AzureML.
Joy Buolamwini, az MIT Media Lab kutatójaként és az Algorithmic Justice League vezetőjeként a gépi tanuláson alapuló rendszerek előítéletei és sztereotípiái ellen harcol. A tudós kiemelte, hogy kutatásaik szerint a sötét bőrrel rendelkező emberek nincsenek megfelelően reprezentálva azokban az adatbázisokban, amelyekkel az automatikus arcfelismerő szoftvereket képezik. Az algoritmusokat nem tanítják meg megfelelően arra, hogy változatos arcokat ismerjenek fel és ez nagyon pontatlan eredményekhez vezet. Holott nagyon is fontos az, hogy a technológia megfelelően működjön - különösen akkor, ha olyan döntéseket hoz, amelyeknek komoly következményeik lehetnek. Tavaly augusztusban például kiderült, hogy a képfelismerő algoritmusok szexisták: amennyiben egy konyhát látnak, akkor azt automatikusan a nőkkel hozzák kapcsolatba.