SG.hu·
Keresés a szavak jelentése szerint
Egy projekt keretében olyan nyílt forráskódú keresőt fejlesztenek amerikai kutatók, amely a szavak jelentése szerint listázza ki a kért fogalommal kapcsolatos általa meglelt találatokat.
A Vermont szövetségi államban található Middlebury College-ben immár ötödik éve dolgoznak a program kifejlesztésén, illetve tökéletesítésén az amerikai szakemberek. A most kiszivárgott információk szerint néhány héten belül már bárki számára elérhető lesz az új kereső. A szemantikus keresésnek nevezett eljárás egyik legegyszerűbb formája, ha a találatokat a szavak jelentése szerint rendezi el a program. A második lehetőség, hogy a fogalmakat szócsoportok és szócsaládok szerint rendezi.
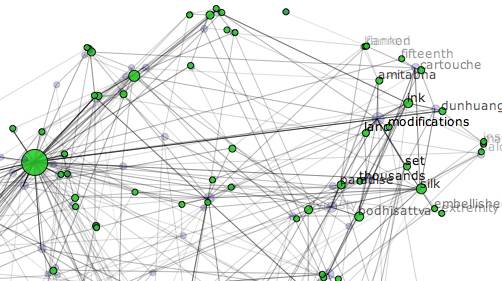
S hogy mit jelent mindez a gyakorlatban? Nos, ha például beírjuk az új keresőbe azt a szót, hogy kutya, akkor a program a hagyományos keresőkkel ellentétben nem azokat az oldalakat fogja kilistázni amelyeken ez a szó szerepel, hanem azokat is, ahol a pudli, a labrador vagy a németjuhász szó található. Aaron Coburn, a Semantic Indexing nevű program vezetője október elején akarja bemutatni az új alkalmazás első változatát. A projekt azonban ettől függetlenül folytatódni fog. A szakemberek ugyanis már egy új verzión dolgoznak, amelyik irodalmi szövegekben (könyvekben, drámákban) lesz képes fogalmak után keresni.
Az alkalmazás képes lesz arra, hogy kikeresse az egy műben szereplő karakterekhez kapcsolódó összes szót, mondatot, majd felállítson egy olyan rendszert, ami a szereplők közötti kapcsolatokat, összefüggéseket mutatja be. Vagyis kikereshető lesz például a Rómeó és Júliában az összes a két főszereplő közötti párbeszéd. A másik alprogram egy blogok közötti kereső létrehozását célozza.
"Remélem, hogy ezeknek a programoknak a segítségével az eddigihez képest egy teljesen más módon is hozzájuthatunk majd a minket érdeklő információkhoz és olyan adatokat is megismerhetünk, amik a hagyományos keresőkkel eddig rejtve maradtak előttünk" - jelentette ki Aaron Coburn.
A Vermont szövetségi államban található Middlebury College-ben immár ötödik éve dolgoznak a program kifejlesztésén, illetve tökéletesítésén az amerikai szakemberek. A most kiszivárgott információk szerint néhány héten belül már bárki számára elérhető lesz az új kereső. A szemantikus keresésnek nevezett eljárás egyik legegyszerűbb formája, ha a találatokat a szavak jelentése szerint rendezi el a program. A második lehetőség, hogy a fogalmakat szócsoportok és szócsaládok szerint rendezi.
S hogy mit jelent mindez a gyakorlatban? Nos, ha például beírjuk az új keresőbe azt a szót, hogy kutya, akkor a program a hagyományos keresőkkel ellentétben nem azokat az oldalakat fogja kilistázni amelyeken ez a szó szerepel, hanem azokat is, ahol a pudli, a labrador vagy a németjuhász szó található. Aaron Coburn, a Semantic Indexing nevű program vezetője október elején akarja bemutatni az új alkalmazás első változatát. A projekt azonban ettől függetlenül folytatódni fog. A szakemberek ugyanis már egy új verzión dolgoznak, amelyik irodalmi szövegekben (könyvekben, drámákban) lesz képes fogalmak után keresni.
Az alkalmazás képes lesz arra, hogy kikeresse az egy műben szereplő karakterekhez kapcsolódó összes szót, mondatot, majd felállítson egy olyan rendszert, ami a szereplők közötti kapcsolatokat, összefüggéseket mutatja be. Vagyis kikereshető lesz például a Rómeó és Júliában az összes a két főszereplő közötti párbeszéd. A másik alprogram egy blogok közötti kereső létrehozását célozza.
"Remélem, hogy ezeknek a programoknak a segítségével az eddigihez képest egy teljesen más módon is hozzájuthatunk majd a minket érdeklő információkhoz és olyan adatokat is megismerhetünk, amik a hagyományos keresőkkel eddig rejtve maradtak előttünk" - jelentette ki Aaron Coburn.