SG.hu·
Míg az MI-cégek égetik a pénzt, addig az adatrendszerezők kaszálnak

A mesterséges intelligencia fejlesztésének élvonalában álló laboratóriumok, mint az OpenAI és az Anthropic, hatalmas adatmennyiségekre támaszkodnak a mesterséges általános intelligencia (AGI) eléréséért folytatott versenyben. Ez óriási költségekkel jár - milliárd dollárokban mérve -, és olyan kevéssé ismert cégek kaszálnak ezen, mint a Mercor és a Handshake.
Brendan Foody 19 évesen alapította a Mercort két középiskolai barátjával, hogy a vele üzleti kapcsolatban álló ismerősei külföldi szoftvermérnököket tudjanak alkalmazni. A cég 2023-ban indult, lényegében egy erősen automatizált munkaerő-közvetítőként, ahol a nyelvi modellek néztek át az önéletrajzokat és vezették le az interjúkat. Néhány hónap alatt a Mercor évesített bevétele elérte az 1 millió dollárt, miközben mérsékelt nyereséget termelt. 2024 elején a Scale AI megkereste őket azzal, hogy 1200 szoftvermérnökre van szükségük. A Scale ekkor már közel 14 milliárd dolláros értékeltséggel rendelkezett - egy évvel később 15 milliárd dollárért vette meg a felét a Meta -, és az MI tréningadatok előállításában volt ismert: világszerte embereket keresett, hogy adatokat címkézzenek fel az önvezető autók, e-kereskedelmi algoritmusok és nyelvi modellekkel működő chatbotok számára. Ahogy az OpenAI, az Anthropic és más cégek chatbotjait kódolásra próbálták tanítani, a Scale-nek szoftvermérnökökre volt szüksége a tréningadatok előállításához.
Foody érezte, hogy ez a helyzet nagy változást jelezhet az MI-iparban. Miután a toborzott mérnökök a kifizetések elmaradására panaszkodtak - a Scale híres volt a kaotikus platformkezeléséről és több jogi eljárás is zajlott ellene Kaliforniában -, Foody úgy döntött, hogy kiiktatja a közvetítőt. 2024 szeptemberében bejelentette, hogy a Mercor évesített bevétele elérte az 500 millió dollárt, így a vállalat az “minden idők leggyorsabban növekvő cége” lett. A legutóbbi befektetési körében a cég értékeltsége 10 milliárd dollárra nőtt. Foody valamint a másik két társalapító 22 évesek, ezzel a világ legfiatalabb, saját erejükből lett milliárdosai.

Brendan Foody
Miközben az MI-infrastruktúráról gyakran a hatalmas adatközpontok építése jut eszünkbe, a tréningadatok iránti verseny hasonlóan intenzív. Az MI-cégek már kimerítették az egyszerűen hozzáférhető adatokat, így a jövőbeni gyors fejlődés kérdésessé válik. Az friss fejlesztések többsége kisebb, szakértők által testreszabott adathalmazokra támaszkodott, például programozás és pénzügy területén, amelyért az MI-cégek prémium árat fizetnek. A befektetők és ipari bennfentesek becslése szerint az idei költés meghaladja a 10 milliárd dollárt, a kiadások nagy része pedig öt-hat vállalatnál koncentrálódik, amelyek már most nyereséget termelnek.
Az adatszolgáltató iparág régóta alulértékelt és kevésbé vonzó terület volt az MI fejlesztésében, de a gépi tanulás ma már elképzelhetetlen ezen ökoszisztéma nélkül. A korai 2010-es évek hatalmas adathalmazait az Amazon Mechanical Turkhez hasonló platformok tették lehetővé, ahol emberek aprópénzért címkéztek képeket. A nyelvi modellek felé történő elmozdulás a ChatGPT elindítása után új átalakulást hozott: az RLHF (reinforcement learning from human feedback) módszerével emberi visszajelzések alapján tanították a modelleket, ezzel javítva a chatbotok válaszadási képességeit.
A Scale mellett a Surge AI is gyorsan nőtt, önfinanszírozottan, magas minőségű adatokat szolgáltatva. A Surge körülbelül 30 dollár óránként fizetett a szakértőknek, például orvosi végzettségű értékelőknek, és az elmúlt évben bevétele meghaladta az 1 milliárd dollárt, felülmúlva a Scale 870 millió dolláros bevételét. A valós világban azonban az MI-modellek gyakran hibáznak: a jogi vagy pénzügyi elemzések sikeressége kontextustól, céltól és közönségtől függ, így a modellek teljesítménye a tesztfeladatok alapján gyakran csalóka. Az MI-laborok ezért további emberi adatokat igényelnek, amelyek valódi feladatokat tükröznek, és ez magyarázza a szoftvermérnökök, pénzügyi szakértők és tanácsadók iránti hatalmas keresletet.
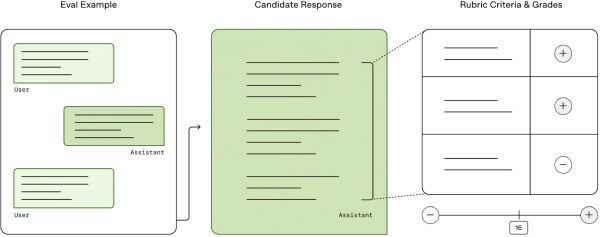
A Mercor, Surge, Handshake AI és mások specializált szakértőket alkalmaznak és komplex, részletes értékelési rubrikákat készítenek, amelyek alapján a modelleket tréningezik. A rubrikák elkészítése rendkívül munkaigényes. Azok, akik ezeken dolgoznak, elmondták, hogy nem ritka, hogy 10 órát vagy annál is többet töltenek egyetlen rubrika kidolgozásával, amely több mint egy tucat különböző kritériumot tartalmazhat. A vállalatok szigorúan őrzik képzési módszereik részleteit, de az OpenAI által a legutóbbi orvosi benchmarkhoz közzétett példa jó képet ad arról, hogy milyenek ezek a módszerek. Ha egy nem reagáló emberről kérdezik, a modell akkor kap jutalmat, ha válasza tartalmazza a pulzus ellenőrzésére, a defibrillátor megkeresésére, a CPR elvégzésére vonatkozó tanácsot és 16 további kritériumot. A benchmarkban közel 50 000 ilyen kritérium található, amelyek különböző promptokra vonatkoznak. Az adatelemzési iparban dolgozók szerint a laboratóriumok tíz- vagy százezres rubrikákat rendelnek, amelyek között képzési futtatásonként több millió kritérium található.
Foody szerint a tanácsadási rubrikák elkészítése azzal kezdődik, hogy létrehozzák az összes olyan iparág taxonómiáját, amelyben a tanácsadó cég működik, majd az összes olyan tanácsadási típust, amelyet az egyes iparágakban végez, végül az összes olyan jelentés- és elemzés-típust, amelyet egy tanácsadó az egyes kategóriákban készíthet. Ezeknek a feladatoknak az elvégzése általában számítógépes munkát igényel, és mindegyik feladathoz rubrika is szükséges. Egy e-mail elküldése számos lépést igényel - böngésző megnyitása, új üzenet létrehozása, begépelése stb. A modellek ezeket a feladatokat egyszerűsített szoftververziókban, úgynevezett megerősítő tanulási környezetekben tanulják meg, amelyeket gyakran MI „edzőtermeknek” neveznek, és ahol a modellek addig próbálkozhatnak, amíg meg nem tanulják, hogyan kell kattintani és húzni az egérrel, hogy jó pontszámot érjenek el a rubrikában. Ezeknek a környezeteknek a piaca is virágzik.
Az értékelési rendszerekhez hasonlóan mindegyiket a felhasználáshoz kell igazítani. A szolgáltatók szerint a legkeresettebb területek azok, amelyek a ellenőrizhetőség és a gazdasági érték ideális egyensúlyát képviselik. A szolgáltatók szerint a legkeresettebb területek azok, amelyek az ellenőrizhetőség és a gazdasági érték ideális egyensúlyát képviselik. A szoftverfejlesztés továbbra is a legnagyobb, ezt követi a pénzügy és a tanácsadás. A jog is népszerű, bár eddig kevésbé ellenőrizhetőnek bizonyult, és ezért kevésbé alkalmas a megerősítéses tanulásra. A fizika, a kémia és a matematika is keresett, de valójában mindenkinek van keresnivalója: vannak hirdetések nukleáris mérnökök és állatidomárok számára is. Az ezzel foglalkozó cégek, mint a Turing, Labelbox, Invisible, Pareto és Micro1, a hagyományos munkaerő-közvetítésről átálltak az MI-tréningadatok biztosítására, és exponenciálisan növelik bevételüket.
Az emberiség összes tudását és szakértelmét ellenőrzőlistákba kódolni hatalmas, talán Don Quijote-i méretű vállalkozás, de az élvonalban lévő laboratóriumok milliárdokat költhetnek erre, és puszta igényük mérete átalakítja az adatipart. Új szereplők tűnnek fel nap mint nap, és mindenki egyre nevesebb szakértőkkel reklámozza magát, akik egyre magasabb díjazásban részesülnek. A Surge a Fields-éremmel kitüntetett matematikusokkal, a Legfelsőbb Bíróság ügyvédeivel és a Harvard történészeivel büszkélkedik. A Mercor a Goldman elemzőivel és a McKinsey tanácsadóival hirdeti magát. A Handshake AI - egy másik gyorsan növekvő szakértői szolgáltató - a Berkeley-i és a Stanford-i fizikusokkal, valamint azzal büszkélkedik, hogy több mint 1000 egyetemről tud hallgatókat toborozni. Még a kisebb, niche szereplők, mint a Sapien, Stellar, Aligned, FlexiBench vagy Mechanize is rengeteg pénzt keresnek a hatalmas piaci igények miatt.
Ezek a vállalatok adják el a “lapátot és csákányt” az MI aranyásóinak, azaz az adatokat és a környezeteket, miközben a laborok milliárdokat költenek a képzésre. De ha a befektetők belefáradnak abba, hogy öntsék a pénzt az MI-modellezőkbe, vagy a laboratóriumok más megközelítést alkalmaznak a képzésben, az katasztrófális következményekkel járhat. Az összes MI-fejlesztő már most is több adatforrást használ, és ahogy a Scale-től való tömeges távozás is mutatja, gyorsan máshova viszik a pénzüket. Mindez heves versenyhez vezet. A vezérigazgatók podcastokban és interjúkban kritizálják riválisaik üzleti modelljeit.
Az egyik úgy gondolja, hogy a legtöbb versenytársa sima emberkereskedő. Foody a Surge-ot és a Scale-t a jól fizetett szakértők korában hagyományos crowdsourcerekként emlegeti. A Handshake ura szerint riválisai több ezer dollárt költenek olyan toborzókra, akik fizikusokat bombáznak a TikTokon, de ők már mind az ő platformján vannak. Mindhárman azt állítják, hogy a Scale-nek már a Meta befektetése előtt is voltak minőségi problémái. Minden alkalommal, amikor ilyen szúrós megjegyzésről számolnak be, a Scale szóvivője visszavág, azzal vádolva Foodyt, hogy publicitást keres, vagy gúnyolva egy céget a hosszú távú tőkebevonási köréért. A Scale jelenleg pereli a Mercort azzal az indokkal, hogy elcsábította az egyik alkalmazottját, aki távozásakor ügyfeleket lopott el.
Most még mindenkinek jut elég pénz. Rubrikákat, környezetet, minden elképzelhető típusú szakértőt akarnak, de a régi típusú adatokat is megvásárolják. Még a Scale is növekszik a Meta felvásárlása utáni visszaesés után, és a főbb ügyfelek bizonyos mértékben visszatértek. Jason Droege ideiglenes vezérigazgató szeptemberben egy interjúban elmondta, hogy a vállalat továbbra is együttműködik a Google-lal, a Microsofttal, az OpenAI-jal és az xAI-jal. Az üzleti MI területén való jobb versenyképesség érdekében a Scale elindított egy „Human Frontier Collective” nevű programot is a számítástechnika, a mérnöki tudományok, a matematika és a kognitív tudományok területén dolgozó fehérgalléros szakemberek számára.
A nemrégiben indult adatkezelő cégek 11 számjegyű értékelései az MI-buborék jeleinek is tekinthetők, de az MI fejlődésének egy bizonyos irányvonalára való fogadásnak is. (Mindkettő igaz lehet.) Az MI-laboratóriumok hatalmas kiadásaikat azzal indokolják, hogy céljuk a mesterséges általános intelligencia terén való áttörés, ami az OpenAI alapokmányában szereplő definíció szerint „magas fokú autonómia” és „az embereknél jobb teljesítmény a legtöbb gazdasági szempontból értékes munkában”. A kifejezés homályos és vitatott, de az általános mesterséges intelligencia egyik feladata az általánosítás. Ha matematikára és könyvelésre tanítjuk, akkor képesnek kell lennie az adóbevallás elkészítésére anélkül, hogy további megerősítő tanulásra lenne szüksége az adójog, az egyes országok adószabályai stb. terén. Egy általános képességű ügynöknek nem kell hatalmas mennyiségű új adat, hogy minden területen mindenféle feladatot el tudjon látni.
„Az MI laboratóriumok által előre jelzett jövőben a teljesítmény növekedésével csökken az emberi adatok iránti igény, egészen addig, amíg az embert teljesen ki lehet vonni a folyamatból” - mondja Daniel Kang, az Illinois-i Egyetem Urbana-Champaign campusának számítástechnika és adattudományi adjunktusa, aki a képzési adatok iránti igényről írt. Ehelyett azonban éppen az ellenkezője tűnik bekövetkezni. A laboratóriumok többet költenek adatokra, mint valaha, és a fejlesztések egyre specifikusabb alkalmazásokhoz szabott, egyedi adatkészletekből származnak. A jelenlegi képzési trendeket figyelembe véve Kang úgy jósolja, hogy a jövőbeli MI-fejlődés elsődleges akadálya az lesz, hogy minden egyes területen magas minőségű emberi adatokat szerezzenek.
Ebben a forgatókönyvben az MI inkább egy „normális technológiának” tűnik, mondta Kang. A normális technológia alatt azt kell érteni, hogy olyan, mint a gőzgépek vagy az internet - potenciálisan átalakító erejű, de nem egy számítógépes isten. Kang feltételezi, hogy ez az oka annak is, hogy a vállalatok kevésbé hajlandóak hangoztatni az adatokra fordított kiadásaikat, mint az adatközpontokra fordítottakat: ez ellentmond a pénzgyűjtési narratívájuknak. Utóbbi forgatókönyvben ugyanis a vállalatoknak mindig új adatokat kell vásárolniuk, amikor egy adott feladatot automatizálni akarnak, és a munkafolyamatok változásával is folyamatosan adatokat kell venniük.
Az adatszolgáltató cégek ebben reménykednek. „A laboratóriumok nagyon szeretnék azt mondani, hogy minél hamarabb rendelkezni fogunk általános szuperintelligenciával” - mondta Foody. „A gyakorlatban azonban a megerősítéses tanulás általánosítási hatótávolsága korlátozott, ezért az összes optimalizálni kívánt területre ki kell dolgozniuk az értékelési rendszereket, és a beruházásaik ezen a területen nagyon gyorsan megugranak.” Más cégek, amelyek szerint a határterületi modellek nem fogják „elérni azt a generalizációs pontot, ahol már csak varázslat van, és mindent meg lehet csinálni” - ahogy Ryan Wexler, a SignalFire AI-infrastruktúra-befektetéseinek vezetője fogalmazott -, arra készülnek, hogy kiszolgálják azt a sok céget, amelyeknek a modelleket a saját céljaikhoz kell igazítaniuk.
A SignalFire a Centaur AI-ba, egy orvosi és tudományos adatokat kezelő vállalatba fektetett be. A Centaur ügyfelei többségében nem vezető MI-laboratóriumok, hanem olyan orvosi intézmények, mint a Memorial Sloan Kettering vagy a Medtronic, amelyek rendkívül specifikus alkalmazásokkal és alacsony hibahatárral rendelkeznek. Tavaly az intelligens matracokat gyártó Eight Sleep vállalat „horkolásérzékelő” funkcióval szerette volna bővíteni ágyainak képességeit. A meglévő modellek nem voltak alkalmasak erre a feladatra, ezért a vállalat felkérte a Centaur-t, hogy több mint 50 000 embert toborozzon a horkolás címkézésére.
„Az istenmodell létrehozására irányuló kísérletekről nem tudom, mi lesz a vége, de nagyon biztos vagyok benne, hogy a kereslet mindenki más körében tovább fog növekedni” - szögezi le Erik Duhaime, a Centaur alapítója és vezérigazgatója. „Mindenkinek azt az álmot adták el, hogy ez könnyű lesz, csak be kell dugni és máris működik” - mondta Duhaime. „Most pedig rájönnek, hogy 'Ó, ezt a saját felhasználási esetünkhöz kell igazítanunk'.”
Ha az AGI megvalósítása képzési rubrikák egyenkénti bevezetésével történik, akkor a jövő fényesnek ígérkezik az adatszolgáltatók számára. Egyes a szakmában dolgozó vezetők szerint az MI-adatok osztályozója lesz a leggyakoribb foglalkozás a bolygón az elkövetkező években, és milliárdok fogják értékelni és képezni a modelleket. A Handshake vezetője egy új munkakategória kialakulását látja, és ezt a tíz évvel ezelőtti Uber-sofőrökhöz hasonlítja. „Hatalmas adat- és értékelésbázisra lesz szükségünk a gazdaság minden ágazatában” - mondta Foody. A Mercorban, mondja, az ügyfélszolgálati csapat válaszol azokra a hibajegyekre, amelyeket az MI-ügynök nem tud kezelni, de frissíti a rubrikákat is, hogy legközelebb tudjon válaszolni ezekre a kérdésekre. „Ha nagy képet nézzük” - mondta -, „úgy tűnik, hogy az egész gazdaság egy megerősítő tanulási környezetté válik.”
Ha a befektetők nem találják ezt a jövőképét olyan vonzónak, akkor vigasztalhatja őket az a tény, hogy legalább valakik megtalálták a módját, hogy pénzt keressenek az MI-vel.
Brendan Foody 19 évesen alapította a Mercort két középiskolai barátjával, hogy a vele üzleti kapcsolatban álló ismerősei külföldi szoftvermérnököket tudjanak alkalmazni. A cég 2023-ban indult, lényegében egy erősen automatizált munkaerő-közvetítőként, ahol a nyelvi modellek néztek át az önéletrajzokat és vezették le az interjúkat. Néhány hónap alatt a Mercor évesített bevétele elérte az 1 millió dollárt, miközben mérsékelt nyereséget termelt. 2024 elején a Scale AI megkereste őket azzal, hogy 1200 szoftvermérnökre van szükségük. A Scale ekkor már közel 14 milliárd dolláros értékeltséggel rendelkezett - egy évvel később 15 milliárd dollárért vette meg a felét a Meta -, és az MI tréningadatok előállításában volt ismert: világszerte embereket keresett, hogy adatokat címkézzenek fel az önvezető autók, e-kereskedelmi algoritmusok és nyelvi modellekkel működő chatbotok számára. Ahogy az OpenAI, az Anthropic és más cégek chatbotjait kódolásra próbálták tanítani, a Scale-nek szoftvermérnökökre volt szüksége a tréningadatok előállításához.
Foody érezte, hogy ez a helyzet nagy változást jelezhet az MI-iparban. Miután a toborzott mérnökök a kifizetések elmaradására panaszkodtak - a Scale híres volt a kaotikus platformkezeléséről és több jogi eljárás is zajlott ellene Kaliforniában -, Foody úgy döntött, hogy kiiktatja a közvetítőt. 2024 szeptemberében bejelentette, hogy a Mercor évesített bevétele elérte az 500 millió dollárt, így a vállalat az “minden idők leggyorsabban növekvő cége” lett. A legutóbbi befektetési körében a cég értékeltsége 10 milliárd dollárra nőtt. Foody valamint a másik két társalapító 22 évesek, ezzel a világ legfiatalabb, saját erejükből lett milliárdosai.
Brendan Foody
Miközben az MI-infrastruktúráról gyakran a hatalmas adatközpontok építése jut eszünkbe, a tréningadatok iránti verseny hasonlóan intenzív. Az MI-cégek már kimerítették az egyszerűen hozzáférhető adatokat, így a jövőbeni gyors fejlődés kérdésessé válik. Az friss fejlesztések többsége kisebb, szakértők által testreszabott adathalmazokra támaszkodott, például programozás és pénzügy területén, amelyért az MI-cégek prémium árat fizetnek. A befektetők és ipari bennfentesek becslése szerint az idei költés meghaladja a 10 milliárd dollárt, a kiadások nagy része pedig öt-hat vállalatnál koncentrálódik, amelyek már most nyereséget termelnek.
Az adatszolgáltató iparág régóta alulértékelt és kevésbé vonzó terület volt az MI fejlesztésében, de a gépi tanulás ma már elképzelhetetlen ezen ökoszisztéma nélkül. A korai 2010-es évek hatalmas adathalmazait az Amazon Mechanical Turkhez hasonló platformok tették lehetővé, ahol emberek aprópénzért címkéztek képeket. A nyelvi modellek felé történő elmozdulás a ChatGPT elindítása után új átalakulást hozott: az RLHF (reinforcement learning from human feedback) módszerével emberi visszajelzések alapján tanították a modelleket, ezzel javítva a chatbotok válaszadási képességeit.
A Scale mellett a Surge AI is gyorsan nőtt, önfinanszírozottan, magas minőségű adatokat szolgáltatva. A Surge körülbelül 30 dollár óránként fizetett a szakértőknek, például orvosi végzettségű értékelőknek, és az elmúlt évben bevétele meghaladta az 1 milliárd dollárt, felülmúlva a Scale 870 millió dolláros bevételét. A valós világban azonban az MI-modellek gyakran hibáznak: a jogi vagy pénzügyi elemzések sikeressége kontextustól, céltól és közönségtől függ, így a modellek teljesítménye a tesztfeladatok alapján gyakran csalóka. Az MI-laborok ezért további emberi adatokat igényelnek, amelyek valódi feladatokat tükröznek, és ez magyarázza a szoftvermérnökök, pénzügyi szakértők és tanácsadók iránti hatalmas keresletet.
A Mercor, Surge, Handshake AI és mások specializált szakértőket alkalmaznak és komplex, részletes értékelési rubrikákat készítenek, amelyek alapján a modelleket tréningezik. A rubrikák elkészítése rendkívül munkaigényes. Azok, akik ezeken dolgoznak, elmondták, hogy nem ritka, hogy 10 órát vagy annál is többet töltenek egyetlen rubrika kidolgozásával, amely több mint egy tucat különböző kritériumot tartalmazhat. A vállalatok szigorúan őrzik képzési módszereik részleteit, de az OpenAI által a legutóbbi orvosi benchmarkhoz közzétett példa jó képet ad arról, hogy milyenek ezek a módszerek. Ha egy nem reagáló emberről kérdezik, a modell akkor kap jutalmat, ha válasza tartalmazza a pulzus ellenőrzésére, a defibrillátor megkeresésére, a CPR elvégzésére vonatkozó tanácsot és 16 további kritériumot. A benchmarkban közel 50 000 ilyen kritérium található, amelyek különböző promptokra vonatkoznak. Az adatelemzési iparban dolgozók szerint a laboratóriumok tíz- vagy százezres rubrikákat rendelnek, amelyek között képzési futtatásonként több millió kritérium található.
Foody szerint a tanácsadási rubrikák elkészítése azzal kezdődik, hogy létrehozzák az összes olyan iparág taxonómiáját, amelyben a tanácsadó cég működik, majd az összes olyan tanácsadási típust, amelyet az egyes iparágakban végez, végül az összes olyan jelentés- és elemzés-típust, amelyet egy tanácsadó az egyes kategóriákban készíthet. Ezeknek a feladatoknak az elvégzése általában számítógépes munkát igényel, és mindegyik feladathoz rubrika is szükséges. Egy e-mail elküldése számos lépést igényel - böngésző megnyitása, új üzenet létrehozása, begépelése stb. A modellek ezeket a feladatokat egyszerűsített szoftververziókban, úgynevezett megerősítő tanulási környezetekben tanulják meg, amelyeket gyakran MI „edzőtermeknek” neveznek, és ahol a modellek addig próbálkozhatnak, amíg meg nem tanulják, hogyan kell kattintani és húzni az egérrel, hogy jó pontszámot érjenek el a rubrikában. Ezeknek a környezeteknek a piaca is virágzik.
Az értékelési rendszerekhez hasonlóan mindegyiket a felhasználáshoz kell igazítani. A szolgáltatók szerint a legkeresettebb területek azok, amelyek a ellenőrizhetőség és a gazdasági érték ideális egyensúlyát képviselik. A szolgáltatók szerint a legkeresettebb területek azok, amelyek az ellenőrizhetőség és a gazdasági érték ideális egyensúlyát képviselik. A szoftverfejlesztés továbbra is a legnagyobb, ezt követi a pénzügy és a tanácsadás. A jog is népszerű, bár eddig kevésbé ellenőrizhetőnek bizonyult, és ezért kevésbé alkalmas a megerősítéses tanulásra. A fizika, a kémia és a matematika is keresett, de valójában mindenkinek van keresnivalója: vannak hirdetések nukleáris mérnökök és állatidomárok számára is. Az ezzel foglalkozó cégek, mint a Turing, Labelbox, Invisible, Pareto és Micro1, a hagyományos munkaerő-közvetítésről átálltak az MI-tréningadatok biztosítására, és exponenciálisan növelik bevételüket.
Az emberiség összes tudását és szakértelmét ellenőrzőlistákba kódolni hatalmas, talán Don Quijote-i méretű vállalkozás, de az élvonalban lévő laboratóriumok milliárdokat költhetnek erre, és puszta igényük mérete átalakítja az adatipart. Új szereplők tűnnek fel nap mint nap, és mindenki egyre nevesebb szakértőkkel reklámozza magát, akik egyre magasabb díjazásban részesülnek. A Surge a Fields-éremmel kitüntetett matematikusokkal, a Legfelsőbb Bíróság ügyvédeivel és a Harvard történészeivel büszkélkedik. A Mercor a Goldman elemzőivel és a McKinsey tanácsadóival hirdeti magát. A Handshake AI - egy másik gyorsan növekvő szakértői szolgáltató - a Berkeley-i és a Stanford-i fizikusokkal, valamint azzal büszkélkedik, hogy több mint 1000 egyetemről tud hallgatókat toborozni. Még a kisebb, niche szereplők, mint a Sapien, Stellar, Aligned, FlexiBench vagy Mechanize is rengeteg pénzt keresnek a hatalmas piaci igények miatt.
Ezek a vállalatok adják el a “lapátot és csákányt” az MI aranyásóinak, azaz az adatokat és a környezeteket, miközben a laborok milliárdokat költenek a képzésre. De ha a befektetők belefáradnak abba, hogy öntsék a pénzt az MI-modellezőkbe, vagy a laboratóriumok más megközelítést alkalmaznak a képzésben, az katasztrófális következményekkel járhat. Az összes MI-fejlesztő már most is több adatforrást használ, és ahogy a Scale-től való tömeges távozás is mutatja, gyorsan máshova viszik a pénzüket. Mindez heves versenyhez vezet. A vezérigazgatók podcastokban és interjúkban kritizálják riválisaik üzleti modelljeit.
Az egyik úgy gondolja, hogy a legtöbb versenytársa sima emberkereskedő. Foody a Surge-ot és a Scale-t a jól fizetett szakértők korában hagyományos crowdsourcerekként emlegeti. A Handshake ura szerint riválisai több ezer dollárt költenek olyan toborzókra, akik fizikusokat bombáznak a TikTokon, de ők már mind az ő platformján vannak. Mindhárman azt állítják, hogy a Scale-nek már a Meta befektetése előtt is voltak minőségi problémái. Minden alkalommal, amikor ilyen szúrós megjegyzésről számolnak be, a Scale szóvivője visszavág, azzal vádolva Foodyt, hogy publicitást keres, vagy gúnyolva egy céget a hosszú távú tőkebevonási köréért. A Scale jelenleg pereli a Mercort azzal az indokkal, hogy elcsábította az egyik alkalmazottját, aki távozásakor ügyfeleket lopott el.
Most még mindenkinek jut elég pénz. Rubrikákat, környezetet, minden elképzelhető típusú szakértőt akarnak, de a régi típusú adatokat is megvásárolják. Még a Scale is növekszik a Meta felvásárlása utáni visszaesés után, és a főbb ügyfelek bizonyos mértékben visszatértek. Jason Droege ideiglenes vezérigazgató szeptemberben egy interjúban elmondta, hogy a vállalat továbbra is együttműködik a Google-lal, a Microsofttal, az OpenAI-jal és az xAI-jal. Az üzleti MI területén való jobb versenyképesség érdekében a Scale elindított egy „Human Frontier Collective” nevű programot is a számítástechnika, a mérnöki tudományok, a matematika és a kognitív tudományok területén dolgozó fehérgalléros szakemberek számára.
A nemrégiben indult adatkezelő cégek 11 számjegyű értékelései az MI-buborék jeleinek is tekinthetők, de az MI fejlődésének egy bizonyos irányvonalára való fogadásnak is. (Mindkettő igaz lehet.) Az MI-laboratóriumok hatalmas kiadásaikat azzal indokolják, hogy céljuk a mesterséges általános intelligencia terén való áttörés, ami az OpenAI alapokmányában szereplő definíció szerint „magas fokú autonómia” és „az embereknél jobb teljesítmény a legtöbb gazdasági szempontból értékes munkában”. A kifejezés homályos és vitatott, de az általános mesterséges intelligencia egyik feladata az általánosítás. Ha matematikára és könyvelésre tanítjuk, akkor képesnek kell lennie az adóbevallás elkészítésére anélkül, hogy további megerősítő tanulásra lenne szüksége az adójog, az egyes országok adószabályai stb. terén. Egy általános képességű ügynöknek nem kell hatalmas mennyiségű új adat, hogy minden területen mindenféle feladatot el tudjon látni.
„Az MI laboratóriumok által előre jelzett jövőben a teljesítmény növekedésével csökken az emberi adatok iránti igény, egészen addig, amíg az embert teljesen ki lehet vonni a folyamatból” - mondja Daniel Kang, az Illinois-i Egyetem Urbana-Champaign campusának számítástechnika és adattudományi adjunktusa, aki a képzési adatok iránti igényről írt. Ehelyett azonban éppen az ellenkezője tűnik bekövetkezni. A laboratóriumok többet költenek adatokra, mint valaha, és a fejlesztések egyre specifikusabb alkalmazásokhoz szabott, egyedi adatkészletekből származnak. A jelenlegi képzési trendeket figyelembe véve Kang úgy jósolja, hogy a jövőbeli MI-fejlődés elsődleges akadálya az lesz, hogy minden egyes területen magas minőségű emberi adatokat szerezzenek.
Ebben a forgatókönyvben az MI inkább egy „normális technológiának” tűnik, mondta Kang. A normális technológia alatt azt kell érteni, hogy olyan, mint a gőzgépek vagy az internet - potenciálisan átalakító erejű, de nem egy számítógépes isten. Kang feltételezi, hogy ez az oka annak is, hogy a vállalatok kevésbé hajlandóak hangoztatni az adatokra fordított kiadásaikat, mint az adatközpontokra fordítottakat: ez ellentmond a pénzgyűjtési narratívájuknak. Utóbbi forgatókönyvben ugyanis a vállalatoknak mindig új adatokat kell vásárolniuk, amikor egy adott feladatot automatizálni akarnak, és a munkafolyamatok változásával is folyamatosan adatokat kell venniük.
Az adatszolgáltató cégek ebben reménykednek. „A laboratóriumok nagyon szeretnék azt mondani, hogy minél hamarabb rendelkezni fogunk általános szuperintelligenciával” - mondta Foody. „A gyakorlatban azonban a megerősítéses tanulás általánosítási hatótávolsága korlátozott, ezért az összes optimalizálni kívánt területre ki kell dolgozniuk az értékelési rendszereket, és a beruházásaik ezen a területen nagyon gyorsan megugranak.” Más cégek, amelyek szerint a határterületi modellek nem fogják „elérni azt a generalizációs pontot, ahol már csak varázslat van, és mindent meg lehet csinálni” - ahogy Ryan Wexler, a SignalFire AI-infrastruktúra-befektetéseinek vezetője fogalmazott -, arra készülnek, hogy kiszolgálják azt a sok céget, amelyeknek a modelleket a saját céljaikhoz kell igazítaniuk.
A SignalFire a Centaur AI-ba, egy orvosi és tudományos adatokat kezelő vállalatba fektetett be. A Centaur ügyfelei többségében nem vezető MI-laboratóriumok, hanem olyan orvosi intézmények, mint a Memorial Sloan Kettering vagy a Medtronic, amelyek rendkívül specifikus alkalmazásokkal és alacsony hibahatárral rendelkeznek. Tavaly az intelligens matracokat gyártó Eight Sleep vállalat „horkolásérzékelő” funkcióval szerette volna bővíteni ágyainak képességeit. A meglévő modellek nem voltak alkalmasak erre a feladatra, ezért a vállalat felkérte a Centaur-t, hogy több mint 50 000 embert toborozzon a horkolás címkézésére.
„Az istenmodell létrehozására irányuló kísérletekről nem tudom, mi lesz a vége, de nagyon biztos vagyok benne, hogy a kereslet mindenki más körében tovább fog növekedni” - szögezi le Erik Duhaime, a Centaur alapítója és vezérigazgatója. „Mindenkinek azt az álmot adták el, hogy ez könnyű lesz, csak be kell dugni és máris működik” - mondta Duhaime. „Most pedig rájönnek, hogy 'Ó, ezt a saját felhasználási esetünkhöz kell igazítanunk'.”
Ha az AGI megvalósítása képzési rubrikák egyenkénti bevezetésével történik, akkor a jövő fényesnek ígérkezik az adatszolgáltatók számára. Egyes a szakmában dolgozó vezetők szerint az MI-adatok osztályozója lesz a leggyakoribb foglalkozás a bolygón az elkövetkező években, és milliárdok fogják értékelni és képezni a modelleket. A Handshake vezetője egy új munkakategória kialakulását látja, és ezt a tíz évvel ezelőtti Uber-sofőrökhöz hasonlítja. „Hatalmas adat- és értékelésbázisra lesz szükségünk a gazdaság minden ágazatában” - mondta Foody. A Mercorban, mondja, az ügyfélszolgálati csapat válaszol azokra a hibajegyekre, amelyeket az MI-ügynök nem tud kezelni, de frissíti a rubrikákat is, hogy legközelebb tudjon válaszolni ezekre a kérdésekre. „Ha nagy képet nézzük” - mondta -, „úgy tűnik, hogy az egész gazdaság egy megerősítő tanulási környezetté válik.”
Ha a befektetők nem találják ezt a jövőképét olyan vonzónak, akkor vigasztalhatja őket az a tény, hogy legalább valakik megtalálták a módját, hogy pénzt keressenek az MI-vel.