SG.hu·
Sora-rivális videógenerátort mutatott be a Google DeepMind
A Google DeepMind, a Google kiemelt MI-kutató laboratóriuma le akarja győzni az OpenAI-t videógenerálásban - ez most sikerült is, legalábbis egy kis időre.
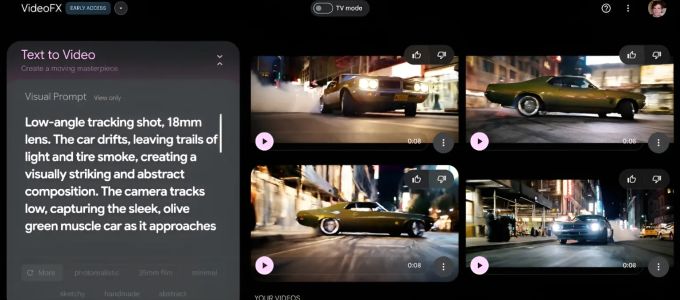
Ma a DeepMind bejelentette a Veo 2-t nevű újgenerációs videogeneráló MI-t, a Veo utódját - elődje a Google portfóliójának egyre több termékét hajtja. A Veo 2 képes két percnél hosszabb klipeket készíteni akár 4k (4096 x 2160 pixel) felbontásban. Ez a Sora felbontásának négyszerese, az OpenAI modellje által elérhető időtartamnak pedig hatszorosa. Ez egyelőre csak elméleti előny, persze. A Google kísérleti videókészítő eszközében, a VideoFX-ben, ahol a Veo 2 most kizárólagosan elérhető, a videók 720p-ben és nyolc másodperc hosszúságban vannak korlátozva. (A Sora akár 1080p-s, 20 másodperces klipeket is képes készíteni.) A VideoFX várólistával vehető csak igénybe, de a Google közölte, hogy még a héten bővíti a hozzáférésre jogosult felhasználók körét.
Eli Collins, a DeepMind termékért felelős alelnöke elmondta, hogy a Google a Vertex AI fejlesztői platformján keresztül teszi elérhetővé a Veo 2-t, „amint a modell készen áll a méretarányos használatra”. "Az elkövetkező hónapokban a felhasználók visszajelzései alapján folytatjuk az iterációt” - mondta Collins. "Arra törekszünk, hogy a Veo 2 frissített képességeit integráljuk a Google ökoszisztémájának meggyőző felhasználási eseteibe. Várhatóan jövőre több frissítést is megosztunk." A Veo-hoz hasonlóan a Veo 2 is képes videókat generálni szöveges felkérés (pl. „Egy autó száguld az autópályán”) vagy szöveg és referenciakép alapján.
Mi az újdonság a Veo 2-ben? Nos, a DeepMind szerint a modell, amely különböző stílusú klipeket képes generálni, jobban „megérti” a fizikát és a kamera vezérlését, és „tisztább” felvételeket készít. A DeepMind a tisztább alatt azt érti, hogy a klipek textúrái és képei élesebbek - különösen a sok mozgást tartalmazó jelenetekben. Ami a továbbfejlesztett kameravezérlést illeti, a Veo 2 segítségével a virtuális kamera pontosabban pozícionálható az általa készített videókban, és a kamera mozgatható, hogy különböző szögekből rögzítse a tárgyakat és az embereket. A DeepMind azt is állítja, hogy a Veo 2 reálisabban tudja modellezni a mozgást, a folyadékdinamikát (például egy bögrébe öntött kávét) és a fény tulajdonságait (például az árnyékokat és a tükröződéseket). Ez a DeepMind szerint különböző lencséket és filmes effekteket, valamint „árnyalt” emberi kifejezéseket is magában foglal.
A DeepMind közzétett néhány, a Veo 2-ből kiválasztott mintát. Ahhoz képest, hogy mesterséges intelligencia által generált videókról van szó, elég jól néznek ki - sőt, kivételesen jól. Úgy tűnik, a Veo 2 jól ért a fénytöréshez és a trükkös folyadékokhoz, például a juharsziruphoz, valamint a Pixar-stílusú animáció utánzásához. De annak ellenére, hogy a DeepMind ragaszkodik ahhoz, hogy a modell kevésbé valószínű, hogy olyan elemeket hallucinál, mint az extra ujjak vagy a „váratlan tárgyak”, a Veo 2 nem tudja teljesen átlépni az uncanny valley-t.
"A koherencia és a következetesség olyan területek, amelyeken még fejlődnünk kell” - mondta Collins. „A Veo képes következetesen betartani egy felszólítást néhány percig, de nem képes hosszú időn keresztül betartani az összetett felszólításokat. Hasonlóképpen a karakterek következetessége is kihívást jelenthet. A bonyolult részletek, a gyors és összetett mozgások generálásában, valamint a realizmus határainak további feszegetésében is van hova fejlődni.” A DeepMind továbbra is együttműködik a művészekkel és producerekkel a videogenerációs modellek és eszközök finomításán - tette hozzá Collins.
„A Veo fejlesztésének kezdete óta olyan alkotókkal kezdtünk el dolgozni, mint Donald Glover, a Weeknd, a d4vd és mások, hogy igazán megértsük a kreatív folyamatukat, és hogy a technológia hogyan segíthetne életre kelteni a víziójukat” - mondta Collins. "A Veo 1 kapcsán az alkotókkal végzett munkánk a Veo 2 fejlesztését is megalapozta, és alig várjuk, hogy megbízható tesztelőkkel és alkotókkal dolgozhassunk együtt, hogy visszajelzéseket kapjunk erről az új modellről.”
A Veo 2-t rengeteg videón képezték ki. Általában így működnek a mesterséges intelligencia modellek: ha valamilyen dologból rengeteg példát kapnak, a modellek olyan mintákat vesznek észre az adatokban, amelyek segítségével új adatokat generálhatnak. A DeepMind nem árulta el, hogy pontosan honnan szerezte be a videókat a Veo 2 betanításához, de a YouTube az egyik lehetséges forrás. A YouTube a Google tulajdonában van, és a DeepMind korábban elismerte, hogy a Veo-hoz hasonló Google-modelleket „lehet”, hogy bizonyos YouTube-tartalmakon képeztek ki. "A Veo-t kiváló minőségű videó-leírás párosításokon képezték ki” - mondta Collins. „A videó-leírás párok egy videó és a hozzá tartozó leírás arról, hogy mi történik a videóban”.
A DeepMind ugyan közzétett olyan eszközöket, amelyekkel a webmesterek megakadályozhatják, hogy a labor botjai képzési adatokat nyerjenek ki a webhelyeikről, a DeepMind nem kínál olyan mechanizmust, amellyel az alkotók eltávolíthatnák műveiket a meglévő képzési készletekből. A laboratórium és anyavállalata azt állítja, hogy a nyilvános adatok felhasználásával történő modellképzés tisztességes felhasználásnak minősül, vagyis a DeepMind úgy véli, hogy nem köteles engedélyt kérni az adatok tulajdonosaitól.
Nem minden alkotó ért egyet ezzel - különösen annak fényében, hogy tanulmányok szerint a következő években több tízezer filmes és televíziós munkahelyet szüntethet meg a mesterséges intelligencia. Több MI-vállalat - köztük a Midjourney nevű, népszerű MI-művészeti alkalmazás mögött álló startup is peres eljárások kereszttüzében áll, amelyekben azzal vádolják őket, hogy a művészek jogait sértik azzal, hogy hozzájárulás nélkül képeznek ki tartalmakat.
„Elkötelezettek vagyunk az alkotókkal és partnereinkkel való együttműködés mellett a közös célok elérése érdekében” - mondta Collins. "Továbbra is együttműködünk a kreatív közösséggel és a szélesebb iparágban tevékenykedő emberekkel, gyűjtjük a meglátásokat és meghallgatjuk a visszajelzéseket, beleértve azokat is, akik a VideoFX-et használják.” A DeepMind szerint a deepfake anyagok kockázatának csökkentése érdekében a DeepMind saját fejlesztésű vízjel-technológiáját, a SynthID-t használják a Veo 2 által generált képkockákba történő láthatatlan jelölések beágyazására. Azonban, mint minden vízjel-technológia, a SynthID sem bolondbiztos.
Annak köszönhetően, ahogyan a mai generatív modellek a betanítás során viselkednek, bizonyos kockázatokat hordoznak magukban, mint például a regurgitáció, ami arra utal, amikor egy modell a betanítási adatok tükörmásolatát generálja. A DeepMind megoldása a prompt-szintű szűrők, többek között az erőszakos, grafikus és explicit tartalmak esetében. Collins szerint a Google kártérítési szabályzata, amely védelmet nyújt bizonyos ügyfelek számára a termékei használatából eredő szerzői jogsértés vádjával szemben, nem vonatkozik a Veo 2-re, amíg az általánosan elérhetővé nem válik.
A Veo 2 mellett a Google DeepMind ma reggel bejelentette a kereskedelmi képgeneráló modelljének, az Imagen 3-nak a frissítését is. Az Imagen 3 új verzióját mától kezdve az ImageFX, a Google képgeneráló eszközének felhasználói is megkapják. A DeepMind szerint „világosabb, jobban megkomponált” képeket és fotókat tud létrehozni olyan stílusokban, mint a fotórealizmus, az impresszionizmus és az anime. "A frissítés az Imagen 3-ra hűségesebben követi az utasításokat, és gazdagabb részleteket és textúrákat renderel” - írja a DeepMind blogbejegyzése. A modell mellett az ImageFX felhasználói felületének frissítése is megtörtént. Mostantól, amikor a felhasználók beírják a felszólításokat, az abban szereplő kulcskifejezések „chiplet”-ekké válnak, a javasolt, kapcsolódó szavak legördülő menüjével. A felhasználók ezeket arra használhatják, hogy megismételjék, amit írtak, vagy választhatnak az automatikusan generált leírások sorából a kérés alatt.
Ma a DeepMind bejelentette a Veo 2-t nevű újgenerációs videogeneráló MI-t, a Veo utódját - elődje a Google portfóliójának egyre több termékét hajtja. A Veo 2 képes két percnél hosszabb klipeket készíteni akár 4k (4096 x 2160 pixel) felbontásban. Ez a Sora felbontásának négyszerese, az OpenAI modellje által elérhető időtartamnak pedig hatszorosa. Ez egyelőre csak elméleti előny, persze. A Google kísérleti videókészítő eszközében, a VideoFX-ben, ahol a Veo 2 most kizárólagosan elérhető, a videók 720p-ben és nyolc másodperc hosszúságban vannak korlátozva. (A Sora akár 1080p-s, 20 másodperces klipeket is képes készíteni.) A VideoFX várólistával vehető csak igénybe, de a Google közölte, hogy még a héten bővíti a hozzáférésre jogosult felhasználók körét.
Eli Collins, a DeepMind termékért felelős alelnöke elmondta, hogy a Google a Vertex AI fejlesztői platformján keresztül teszi elérhetővé a Veo 2-t, „amint a modell készen áll a méretarányos használatra”. "Az elkövetkező hónapokban a felhasználók visszajelzései alapján folytatjuk az iterációt” - mondta Collins. "Arra törekszünk, hogy a Veo 2 frissített képességeit integráljuk a Google ökoszisztémájának meggyőző felhasználási eseteibe. Várhatóan jövőre több frissítést is megosztunk." A Veo-hoz hasonlóan a Veo 2 is képes videókat generálni szöveges felkérés (pl. „Egy autó száguld az autópályán”) vagy szöveg és referenciakép alapján.
Mi az újdonság a Veo 2-ben? Nos, a DeepMind szerint a modell, amely különböző stílusú klipeket képes generálni, jobban „megérti” a fizikát és a kamera vezérlését, és „tisztább” felvételeket készít. A DeepMind a tisztább alatt azt érti, hogy a klipek textúrái és képei élesebbek - különösen a sok mozgást tartalmazó jelenetekben. Ami a továbbfejlesztett kameravezérlést illeti, a Veo 2 segítségével a virtuális kamera pontosabban pozícionálható az általa készített videókban, és a kamera mozgatható, hogy különböző szögekből rögzítse a tárgyakat és az embereket. A DeepMind azt is állítja, hogy a Veo 2 reálisabban tudja modellezni a mozgást, a folyadékdinamikát (például egy bögrébe öntött kávét) és a fény tulajdonságait (például az árnyékokat és a tükröződéseket). Ez a DeepMind szerint különböző lencséket és filmes effekteket, valamint „árnyalt” emberi kifejezéseket is magában foglal.
A DeepMind közzétett néhány, a Veo 2-ből kiválasztott mintát. Ahhoz képest, hogy mesterséges intelligencia által generált videókról van szó, elég jól néznek ki - sőt, kivételesen jól. Úgy tűnik, a Veo 2 jól ért a fénytöréshez és a trükkös folyadékokhoz, például a juharsziruphoz, valamint a Pixar-stílusú animáció utánzásához. De annak ellenére, hogy a DeepMind ragaszkodik ahhoz, hogy a modell kevésbé valószínű, hogy olyan elemeket hallucinál, mint az extra ujjak vagy a „váratlan tárgyak”, a Veo 2 nem tudja teljesen átlépni az uncanny valley-t.
"A koherencia és a következetesség olyan területek, amelyeken még fejlődnünk kell” - mondta Collins. „A Veo képes következetesen betartani egy felszólítást néhány percig, de nem képes hosszú időn keresztül betartani az összetett felszólításokat. Hasonlóképpen a karakterek következetessége is kihívást jelenthet. A bonyolult részletek, a gyors és összetett mozgások generálásában, valamint a realizmus határainak további feszegetésében is van hova fejlődni.” A DeepMind továbbra is együttműködik a művészekkel és producerekkel a videogenerációs modellek és eszközök finomításán - tette hozzá Collins.
„A Veo fejlesztésének kezdete óta olyan alkotókkal kezdtünk el dolgozni, mint Donald Glover, a Weeknd, a d4vd és mások, hogy igazán megértsük a kreatív folyamatukat, és hogy a technológia hogyan segíthetne életre kelteni a víziójukat” - mondta Collins. "A Veo 1 kapcsán az alkotókkal végzett munkánk a Veo 2 fejlesztését is megalapozta, és alig várjuk, hogy megbízható tesztelőkkel és alkotókkal dolgozhassunk együtt, hogy visszajelzéseket kapjunk erről az új modellről.”
A Veo 2-t rengeteg videón képezték ki. Általában így működnek a mesterséges intelligencia modellek: ha valamilyen dologból rengeteg példát kapnak, a modellek olyan mintákat vesznek észre az adatokban, amelyek segítségével új adatokat generálhatnak. A DeepMind nem árulta el, hogy pontosan honnan szerezte be a videókat a Veo 2 betanításához, de a YouTube az egyik lehetséges forrás. A YouTube a Google tulajdonában van, és a DeepMind korábban elismerte, hogy a Veo-hoz hasonló Google-modelleket „lehet”, hogy bizonyos YouTube-tartalmakon képeztek ki. "A Veo-t kiváló minőségű videó-leírás párosításokon képezték ki” - mondta Collins. „A videó-leírás párok egy videó és a hozzá tartozó leírás arról, hogy mi történik a videóban”.
A DeepMind ugyan közzétett olyan eszközöket, amelyekkel a webmesterek megakadályozhatják, hogy a labor botjai képzési adatokat nyerjenek ki a webhelyeikről, a DeepMind nem kínál olyan mechanizmust, amellyel az alkotók eltávolíthatnák műveiket a meglévő képzési készletekből. A laboratórium és anyavállalata azt állítja, hogy a nyilvános adatok felhasználásával történő modellképzés tisztességes felhasználásnak minősül, vagyis a DeepMind úgy véli, hogy nem köteles engedélyt kérni az adatok tulajdonosaitól.
Nem minden alkotó ért egyet ezzel - különösen annak fényében, hogy tanulmányok szerint a következő években több tízezer filmes és televíziós munkahelyet szüntethet meg a mesterséges intelligencia. Több MI-vállalat - köztük a Midjourney nevű, népszerű MI-művészeti alkalmazás mögött álló startup is peres eljárások kereszttüzében áll, amelyekben azzal vádolják őket, hogy a művészek jogait sértik azzal, hogy hozzájárulás nélkül képeznek ki tartalmakat.
„Elkötelezettek vagyunk az alkotókkal és partnereinkkel való együttműködés mellett a közös célok elérése érdekében” - mondta Collins. "Továbbra is együttműködünk a kreatív közösséggel és a szélesebb iparágban tevékenykedő emberekkel, gyűjtjük a meglátásokat és meghallgatjuk a visszajelzéseket, beleértve azokat is, akik a VideoFX-et használják.” A DeepMind szerint a deepfake anyagok kockázatának csökkentése érdekében a DeepMind saját fejlesztésű vízjel-technológiáját, a SynthID-t használják a Veo 2 által generált képkockákba történő láthatatlan jelölések beágyazására. Azonban, mint minden vízjel-technológia, a SynthID sem bolondbiztos.
Annak köszönhetően, ahogyan a mai generatív modellek a betanítás során viselkednek, bizonyos kockázatokat hordoznak magukban, mint például a regurgitáció, ami arra utal, amikor egy modell a betanítási adatok tükörmásolatát generálja. A DeepMind megoldása a prompt-szintű szűrők, többek között az erőszakos, grafikus és explicit tartalmak esetében. Collins szerint a Google kártérítési szabályzata, amely védelmet nyújt bizonyos ügyfelek számára a termékei használatából eredő szerzői jogsértés vádjával szemben, nem vonatkozik a Veo 2-re, amíg az általánosan elérhetővé nem válik.
A Veo 2 mellett a Google DeepMind ma reggel bejelentette a kereskedelmi képgeneráló modelljének, az Imagen 3-nak a frissítését is. Az Imagen 3 új verzióját mától kezdve az ImageFX, a Google képgeneráló eszközének felhasználói is megkapják. A DeepMind szerint „világosabb, jobban megkomponált” képeket és fotókat tud létrehozni olyan stílusokban, mint a fotórealizmus, az impresszionizmus és az anime. "A frissítés az Imagen 3-ra hűségesebben követi az utasításokat, és gazdagabb részleteket és textúrákat renderel” - írja a DeepMind blogbejegyzése. A modell mellett az ImageFX felhasználói felületének frissítése is megtörtént. Mostantól, amikor a felhasználók beírják a felszólításokat, az abban szereplő kulcskifejezések „chiplet”-ekké válnak, a javasolt, kapcsolódó szavak legördülő menüjével. A felhasználók ezeket arra használhatják, hogy megismételjék, amit írtak, vagy választhatnak az automatikusan generált leírások sorából a kérés alatt.