SG.hu·
Az internetet működtető szöveges fájl

Évtizedekig a robots.txt szabályozta a keresők viselkedését, de ahogy a mesterséges intelligenciával foglalkozó cégek gátlástalanul egyre több adatra vágynak, a web alapvető társadalmi szerződése kezd szétesni.
Három évtizeden át egy apró szövegfájl tartotta távol az internetet a káosztól. Ennek a szöveges fájlnak nincs különösebb jogi vagy technikai tekintélye, és még csak nem is különösebben bonyolult. Egy kézfogásos megállapodást jelent az internet néhány legkorábbi úttörője között arról, hogy tiszteletben tartják egymás kívánságait, és úgy építik fel az internetet, hogy az mindenki számára előnyös legyen. Ez egy mini alkotmány az internet számára, kódolva. A robots.txt nevet viseli, és általában a weblapok doménjének gyökerében található. Ez a fájl lehetővé teszi bárki számára, aki weboldalt üzemeltet - legyen az nagy vagy kicsi, főzőblog vagy multinacionális nagyvállalat -, hogy megmondja a világhálónak ki léphet be és ki nem. Mely keresőmotorok indexelhetik a webhelyet vagy hogy milyen archiválási projektek menthetik el az oldalt - ezt minden weblaptulajdonos saját maga döntheti el és kommunikálhatja a világhálóval.
Nem tökéletes rendszer, de működik. Régebben legalábbis működött. Évtizedekig a robots.txt fő fókusza a keresőmotorokra irányult; azok átnézhették az oldalt, cserébe pedig megígérték, hogy látogatókat hoznak. Mostanra a mesterséges intelligencia megváltoztatta az egyenletet: a webes cégek minden elérhető adatot felhasználnak arra, hogy hatalmas mennyiségű képzési adathalmazt hozzanak létre, hogy olyan modelleket és termékeket hozzanak létre, amelyek esetleg egyáltalán nem veszik tudomásul egy letöltött weblap létezését. A robots.txt fájl egy adok-kapok rendszert szabályoz, de az MI csak kapok, és nem adok. De mostanra már annyi pénz van a mesterséges intelligenciában, és a technológiai színvonal olyan gyorsan változik, hogy sok webhelytulajdonos nem tud lépést tartani vele. És a robots.txt és a web egésze mögött álló alapvető megállapodás sem biztos, hogy képes lépést tartani.
Az internet kezdeti időszakában a robotok sokféle néven futottak: pókok, lánctalpasok, férgek, WebAnts, webkúszók. Legtöbbször jó szándékkal építették őket. 1993 környékén a fejlesztők könyvtárakat akartak létrehozni a menő új webhelyekről, vagy ellenőrizni, hogy a saját webhelyük megfelelően működik-e. Jóval ezután jelentek csak meg a keresőmotorok, és azokban az időkben az internet nagy része elférhetett egy mai számítógép merevlemezén. Az egyetlen igazi problémát akkoriban a forgalom jelentette: az internet-hozzáférés lassú és drága volt mind a honlapot megtekintő személy, mind a tárhelyszolgáltató számára. Ha valaki a saját számítógépén tárolta a weboldalát - ahogyan azt sokan tették -, akkor elég volt néhány túlbuzgó robot és máris elromlottak a dolgok.
1994-ben egy Martijn Koster nevű szoftvermérnök más webes adminisztrátorok és fejlesztők egy csoportjával együtt egy olyan megoldást dolgozott ki, amelyet Robots Exclusion Protocolnak neveztek el. A javaslat elég egyszerű volt: arra kérte a webfejlesztőket, hogy adjanak hozzá egy egyszerű szöveges fájlt a doménjükhöz, amely meghatározza, hogy mely robotok nem vizsgálhatják át az oldalukat, illetve felsorolja azokat az oldalakat, amelyek minden robot számára tiltottak. A robotkészítők számára az alku még egyszerűbb volt: tartsák tiszteletben a szöveges fájl kívánságait.
Koster már a kezdetektől fogva világossá tette, hogy nem gyűlöli a robotokat, és nem is akar megszabadulni tőlük. "A robotok a web azon kevés aspektusai közé tartoznak, amelyek működési problémákat és az embereknek bánatot okoznak" - írta 1994 elején egy WWW-Talk nevű levelezőlistára küldött e-mailjében, amely listán olyan korai internet-pionírok is részt vettek, mint Tim Berners-Lee vagy Marc Andreessen. "Ugyanakkor hasznos szolgáltatásokat nyújtanak." Koster óva intett attól, hogy arról vitatkozzunk, hogy a robotok jók vagy rosszak - ez nem számít, mert léteznek és nem fognak eltűnni. Ő egyszerűen csak egy olyan rendszert próbált megtervezni, amely "minimalizálhatja a problémákat, és talán maximalizálhatja az előnyöket".
Az év nyarára a javaslata szabvány lett - nem hivatalos, de többé-kevésbé általánosan elfogadott. Koster júniusban ismét megkereste a WWW-Talk csoportot egy frissítéssel. "Röviden szólva ez egy olyan módszer, amellyel a robotokat el lehet terelni a webszerver URL-tartományának bizonyos területeitől, egy egyszerű szöveges fájlnak a szerveren való elhelyezésével" - írta. "Ez különösen akkor hasznos, ha nagy archívumokat, hatalmas URL-fákkal rendelkező CGI-szkripteket, ideiglenes információkat tárolsz, vagy egyszerűen csak nem akarsz robotokat kiszolgálni." Létrehozott egy tematikus levelezőlistát, amelynek tagjai megállapodtak az ilyen szövegfájlok néhány alapvető szintaxisában és szerkezetében, és a fájl nevét RobotsNotWanted.txt-ről egyszerű robots.txt-re változtatták. Nagyjából mindenki egyetértett a támogatásában, és a következő 30 év nagy részében ez elég jól működött.
De az internet már nem fér el egy merevlemezen, és a robotok sokkal erősebbek. A Google arra használja őket, hogy a teljes webet feltérképezze és indexelje a keresőmotorja számára, és évente több milliárd dollárt hoz a vállalatnak. A Bing lánctalpasai ugyanezt teszik, a Microsoft pedig más keresőmotoroknak és vállalatoknak licenceli adatbázisát. Az Internet Archive botok segítségével tárolja a weboldalakat az utókor számára. Az Amazon webkúszói termékinformációkat keresve járják az internetet, és egy nemrégiben indított trösztellenes per szerint a vállalat arra használja ezeket az információkat, hogy megbüntesse azokat az eladókat, akik más honlapokon jobb ajánlatokat kínálnak. Az OpenAI-hoz hasonló mesterséges intelligenciával foglalkozó cégek a webet letöltve képeznek ki olyan nagyméretű nyelvi modelleket, amelyek ismét alapvetően megváltoztathatják az információhoz való hozzáférés és az információmegosztás módját.
Az internet letöltésének, tárolásának, rendszerezésének és lekérdezésének képessége minden vállalat vagy fejlesztő számára nagy mennyiségű ismeretet biztosít, amellyel dolgozhat. Az elmúlt egy évben az olyan mesterséges intelligencia termékek, mint a ChatGPT, és az ezek alapjául szolgáló nagyméretű nyelvi modellek elterjedése a kiváló minőségű képzési adatokat az internet egyik legértékesebb árucikkévé tette. Ez arra késztette a különböző internetszolgáltatókat, hogy újragondolják a szervereiken tárolt adatok értékét, és újragondolják, hogy ki mihez férhet hozzá. Ha túlságosan megengedő vagy, akkor a weboldalad elveszítheti minden értékét; ha túlságosan korlátozó vagy, akkor láthatatlanná válhatsz.
Sokféle internetes robot van. Egy teljesen ártatlan robot körbemászik, és ellenőrzi, hogy az oldalon található linkek továbbra is más élő oldalakra vezetnek-e. Egy sokkal okosabb verzió minden e-mail címet és telefonszámot begyűjt, amit csak talál. A legelterjedtebb és jelenleg legvitatottabb azonban egy egyszerű webkúszó, amelynek feladata, hogy az internet minél nagyobb részét megtalálja és letöltse, amit csak tud.
A webkúszók általában meglehetősen egyszerűek. Egy jól ismert weboldalon kezdik, mint például a wikipedia.org vagy egy neves híroldal. A lánctalpas letölti ezt az első oldalt, és elraktározza valahol, majd automatikusan rákattint minden linkre azon az oldalon, letölti az összeset, rákattint az összes linkre mindegyikben, és így terjeszkedik a weben. Elegendő idővel és elegendő számítási erőforrással végül több milliárd weboldalt talál és tölt le. A kompromisszum meglehetősen egyszerű: ha a Google be tudja járni az oldaladat, akkor indexelni is tudja, és megjelenítheti a keresési eredmények között.
A Google 2019-es becslése szerint több mint 500 millió weboldalon volt robots.txt oldal, amely megszabja, hogy ezek a botok hozzáférhetnek-e és mihez. Ezeknek az oldalaknak a felépítése általában nagyjából ugyanaz: megnevezi a "User-agent" nevet, amely a bot nevére utal, amikor azonosítják magukat egy szervernél. A Google ügynöke a Googlebot; az Amazoné az Amazonbot; a Bingé a Bingbot; az OpenAI-é a GPTBot. A Pinterest, a LinkedIn, a Twitter és sok más webhely és szolgáltatás rendelkezik saját botokkal, amelyek közül nem mindegyik kerül megemlítésre minden oldalon. (A Wikipedia és a Facebook két olyan platform, ahol különösen alapos a robotok felsorolása.) A robots.txt oldal felsorolja a webhely azon részeit vagy oldalait, amelyekhez az adott ügynök nem férhet hozzá, valamint a megengedett kivételeket. Ha a sorban csak annyi áll, hogy "Letiltás: /", akkor a bot nem szívesen látott felhasználó.
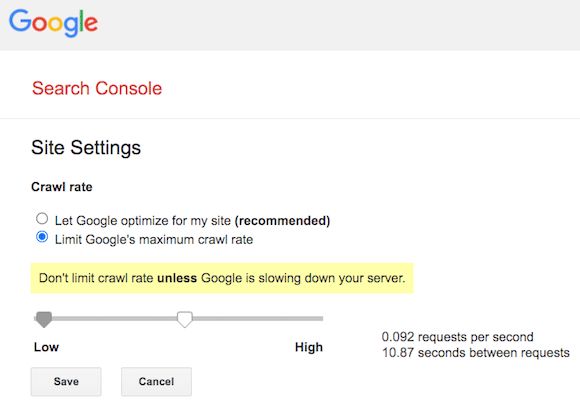
Régen volt már, hogy egy szerver túlterhelése valós probléma legyen. "Manapság általában kevésbé a weboldalon használt erőforrásokról, és inkább a személyes preferenciákról van szó" - mondja John Mueller, a Google keresési tanácsadója. "Mit szeretnél, hogy feltérképezzenek, indexeljenek és miegymás?". A legnagyobb kérdés, amelyre a legtöbb webhelytulajdonosnak a múltban választ kellett adnia az volt, hogy engedélyezzék-e a Googlebotnak, hogy feltérképezze webhelyüket. (Az, hogy a Google hogyan és hol jeleníti meg az oldalt a keresési eredményekben, természetesen teljesen más tészta). A kérdés az, hogy hajlandó vagy-e hagyni, hogy a Google felfalja a sávszélességed egy részét, és letöltse az oldalad egy példányát a kereséssel járó láthatóságért cserébe.
A Google segít a botja lelassításában, hogy ne terhelje túl a webszervert
A legtöbb weboldal számára ez egyértelmű üzlet volt. "A Google a legfontosabb pókunk" - mondja Tony Stubblebine, a Medium vezérigazgatója. A Google letöltheti a Medium összes oldalát, "cserébe pedig jelentős mennyiségű forgalmat kapunk. Mindenki nyer. Mindenki így gondolja". Ez az az alku, amit a Google az internet egészével kötött, hogy a forgalmat más weboldalakra irányítja, miközben hirdetéseket ad el a keresési eredmények ellenében. És a Google minden jel szerint jó polgára volt a robots.txt-nek. "Nagyjából az összes ismert keresőmotor megfelel ennek" - mondja a Google munkatársa, Mueller. "Örülnek, hogy képesek feltérképezni a webet, de nem akarják bosszantani vele az embereket. Megkönnyíti mindenki életét".
Az elmúlt egy évben azonban a mesterséges intelligencia térnyerése felborította ezt az egyenletet. Sok kiadó és platform számára az, hogy az adataikat a képzési adatokért feltérképezik, kevésbé tűnt kereskedésnek, mint inkább lopásnak. "Az MI-vállalatokkal kapcsolatban elég hamar rájöttünk," mondja Stubblebine, "hogy ez nem csak, hogy nem értékcsere, de egyáltalán nem kapunk érte cserébe semmit. Szó szerint nullát." Amikor Stubblebine tavaly ősszel bejelentette, hogy a Medium blokkolni fogja a mesterséges intelligencia botokat, azt írta, hogy "a mesterséges intelligenciával foglalkozó cégek értéket szívnak ki, hogy az internetes olvasókat spameljék".
Az elmúlt egy évben a médiaipar nagy része csatlakozott Stubblebine véleményéhez. "Nem hisszük, hogy a BBC adatainak jelenlegi, engedélyünk nélküli letöltése az MI modellek képzése érdekében közérdekű" - írta tavaly ősszel a BBC külföldért felelős igazgatója, Rhodri Talfan Davies, aki bejelentette, hogy a BBC is blokkolni fogja az OpenAI botját. A New York Times is blokkolta a GPTBotot, hónapokkal azelőtt, hogy pert indított volna az OpenAI ellen, azt állítva, hogy az OpenAI modelljeit "a The Times több millió, szerzői jogvédelem alatt álló hírcikkének, mélyreható nyomozásának, véleménycikkeinek, ismertetőinek, útmutatóinak és egyéb cikkeinek másolásával és felhasználásával építették fel". Ben Welsh, a Reuters híralkalmazások szerkesztője által készített tanulmány szerint a megkérdezett 1156 kiadóból 606 blokkolta a GPTBotot a robots.txt fájljában.
Nem csak a kiadókról van szó. Az Amazon, a Facebook, a Pinterest, a WikiHow, a WebMD és számos más platform kifejezetten blokkolja a GPTBot hozzáférését néhány vagy az összes weboldalukhoz. A legtöbb ilyen robots.txt oldalon az OpenAI GPTBotja az egyetlen olyan bot, amelyet kifejezetten és teljes mértékben tiltanak. De rengeteg más MI-specifikus bot is elkezdte feltérképezni a webet, mint például az Anthropic anthropic-ai és a Google-Extended. Az Originality.AI tavaly őszi tanulmánya szerint a világháló 1000 legjobb webhelye közül 306 blokkolta a GPTBotot, de csak 85 blokkolta a Google-Extendedet és 28 az anthropic-ai-t.
Vannak olyan botok, amelyeket mind a webes kereséshez, mind a mesterséges intelligenciához használnak. A Common Crawl nevű szervezet által működtetett CCBot keresőmotoros célokra pásztázza a webet, de adatait az OpenAI, a Google és mások is használják modelljeik betanításához. A Microsoft Bingbotja egyszerre kereső és MI-kúszó. És ezek csak azok a botok, amelyek azonosítják magukat - sokan mások viszonylag titokban próbálnak működni, így nehéz őket megállítani vagy egyáltalán megtalálni a többi webes forgalom tengerében. Bármelyik kellően népszerű weboldal esetében a sunyi botok megtalálása tű a szénakazalban probléma.
A GPTBot nagyrészt azért vált a robots.txt fő gonosztevőjévé, mert az OpenAI lehetővé tette, hogy ez megtörténjen. A vállalat közzétett egy oldalt arról, hogyan lehet blokkolni a GPTBotot, és úgy építette fel a botját, hogy minden alkalommal, amikor megközelít egy webhelyet, hangosan azonosítja magát. Természetesen mindezt azután tette, hogy kiképezte a mögöttes modelleket, amelyek ilyen erőssé tették, és csak azután, hogy a technológiai ökoszisztéma fontos részévé vált. De az OpenAI stratégiai vezetője, Jason Kwon szerint ez a lényeg. "Mi egy ökoszisztéma szereplői vagyunk" - mondja. "Ha ebben az ökoszisztémában nyílt módon akarunk részt venni, akkor ez a kölcsönös kereskedelem, ami mindenkit érdekel". Szerinte e kereskedelem nélkül a web elkezd visszahúzódni, bezárulni - és ez rossz az OpenAI-nak és mindenkinek. "Mindezt azért csináljuk, hogy a web nyitott maradhasson".
Alapértelmezés szerint a botkizárási protokoll mindig is megengedő volt. Koster 30 évvel ezelőtt úgy vélte, hogy a legtöbb robot jó, és jó emberek készítik, ezért alapértelmezésben engedélyezi őket. Ez nagyjából helyes döntés volt. "Szerintem az internet alapvetően egy szociális lény" - mondja az OpenAI-s Kwon - "és úgy tűnik, hogy ez a sok évtizeden át tartó üzlet bevált". Szerinte az OpenAI szerepe ennek a megállapodásnak a betartásában az, hogy a ChatGPT a legtöbb felhasználó számára ingyenes maradjon - így visszaadva ezt az értéket -, és tiszteletben tartsa a robotok szabályait. A robots.txt azonban nem jogi dokumentum - és 30 évvel a létrehozása után még mindig az összes érintett fél jóindulatán múlik.
A robotok letiltása a robots.txt oldalon olyan, mint egy "Belépni tilos" tábla kirakása - üzenetet küld, de a bíróságon nem fog megállni. Bármely bot, amely figyelmen kívül akarja hagyni a robots.txt-t, egyszerűen megteheti, és nem kell tartania a következményektől. Az Internet Archive például 2017-ben egyszerűen bejelentette, hogy többé nem tartja be a robots.txt szabályait. "Idővel megfigyeltük, hogy a keresőmotorok botjait célzó robots.txt fájlok nem feltétlenül szolgálják az archiválási céljainkat" - írta akkor Mark Graham, az Internet Archive Wayback Machine igazgatója. És ennyi volt.
Ahogy az MI-vállalatok tovább szaporodnak, és a botok egyre gátlástalanabbá válnak, mindenkinek, aki ki akarja várni az MI korszak eljövetelét, egy végtelen játékban kell részt vennie. Minden egyes robotot külön-külön meg kell állítania, ha ez egyáltalán lehetséges, miközben számolnia kell a mellékhatásokkal is. Ha az MI valóban a keresés jövője - ahogyan azt a Google és mások megjósolták - akkor az MI-botok blokkolása rövid távon győzelmet, hosszú távon azonban katasztrófát jelenthet.
Mindkét oldalon vannak olyanok, akik szerint jobb, erősebb és merevebb eszközökre van szükség a botok kezelésére. Azzal érvelnek, hogy túl sok pénz forog kockán, és túl sok új és szabályozatlan felhasználási eset van ahhoz, hogy arra hagyatkozhassunk, hogy mindenki csak úgy beleegyezik, hogy helyesen cselekszik. "Bár sok szereplőnek van némi önszabályozó mechanizmusa a botok használatára" - írta két, a technológiával foglalkozó ügyvéd a webes lánctalpasok jogszerűségéről szóló 2019-es tanulmányában -, "a szabályok összességében túl gyengék, és túl nehéz őket kikényszeríteni".
Egyes kiadók részletesebb ellenőrzést szeretnének mind a feltérképezés, mind a felhasználás tekintetében, a robots.txt általános igen-vagy-nem engedélyek helyett. A Google néhány évvel ezelőtt erőfeszítéseket tett annak érdekében, hogy a Robots Exclusion Protocol hivatalos, formalizált szabvány legyen, és szintén a robots.txt visszaszorítását szorgalmazta, arra hivatkozva, hogy ez egy régi szabvány, és túl sok webhely nem figyel oda rá. "A meglévő webes kiadói ellenőrzések az új mesterséges intelligencia és kutatási felhasználási esetek előtt kerültek kidolgozásra" - írta tavaly Danielle Romain, a Google bizalomért felelős alelnöke. "Úgy véljük, hogy itt az ideje, hogy a webes és az MI közösségek további gépi olvasású eszközöket vizsgáljanak meg a választás és ellenőrzés érdekében az újonnan megjelenő MI és kutatási felhasználási esetek számára."
Még akkor is, ha a mesterséges intelligenciával foglalkozó vállalatoknak szabályozási és jogi kérdésekkel kell szembenézniük azzal kapcsolatban, hogy hogyan építik fel és képzik ki modelljeiket, ezek a modellek folyamatosan fejlődnek, és úgy tűnik, minden nap új vállalatok indulnak. A kisebb és nagyobb weboldalak döntés előtt állnak: alávetik magukat az MI forradalomnak, vagy ellenállnak neki. Azok számára, akik a kívülállást választják, a legerősebb fegyverük egy három évtizeddel ezelőtti megállapodás, amelyet a világháló néhány legelső és legoptimistább hívője kötött. Ők hittek abban, hogy az internet egy jó hely, tele jó emberekkel, akik mindenekelőtt azt akarták, hogy az internet jó dolog legyen. Abban a világban és az interneten elég volt a vezérléshez, ha egy szöveges fájlban kifejtettük a kívánságainkat. Most, hogy a mesterséges intelligencia újra át fogja alakítani az internet kultúráját és gazdaságát, a szerény, egyszerű szöveges fájl kezd kissé régimódinak tűnni.
Három évtizeden át egy apró szövegfájl tartotta távol az internetet a káosztól. Ennek a szöveges fájlnak nincs különösebb jogi vagy technikai tekintélye, és még csak nem is különösebben bonyolult. Egy kézfogásos megállapodást jelent az internet néhány legkorábbi úttörője között arról, hogy tiszteletben tartják egymás kívánságait, és úgy építik fel az internetet, hogy az mindenki számára előnyös legyen. Ez egy mini alkotmány az internet számára, kódolva. A robots.txt nevet viseli, és általában a weblapok doménjének gyökerében található. Ez a fájl lehetővé teszi bárki számára, aki weboldalt üzemeltet - legyen az nagy vagy kicsi, főzőblog vagy multinacionális nagyvállalat -, hogy megmondja a világhálónak ki léphet be és ki nem. Mely keresőmotorok indexelhetik a webhelyet vagy hogy milyen archiválási projektek menthetik el az oldalt - ezt minden weblaptulajdonos saját maga döntheti el és kommunikálhatja a világhálóval.
Nem tökéletes rendszer, de működik. Régebben legalábbis működött. Évtizedekig a robots.txt fő fókusza a keresőmotorokra irányult; azok átnézhették az oldalt, cserébe pedig megígérték, hogy látogatókat hoznak. Mostanra a mesterséges intelligencia megváltoztatta az egyenletet: a webes cégek minden elérhető adatot felhasználnak arra, hogy hatalmas mennyiségű képzési adathalmazt hozzanak létre, hogy olyan modelleket és termékeket hozzanak létre, amelyek esetleg egyáltalán nem veszik tudomásul egy letöltött weblap létezését. A robots.txt fájl egy adok-kapok rendszert szabályoz, de az MI csak kapok, és nem adok. De mostanra már annyi pénz van a mesterséges intelligenciában, és a technológiai színvonal olyan gyorsan változik, hogy sok webhelytulajdonos nem tud lépést tartani vele. És a robots.txt és a web egésze mögött álló alapvető megállapodás sem biztos, hogy képes lépést tartani.
Az internet kezdeti időszakában a robotok sokféle néven futottak: pókok, lánctalpasok, férgek, WebAnts, webkúszók. Legtöbbször jó szándékkal építették őket. 1993 környékén a fejlesztők könyvtárakat akartak létrehozni a menő új webhelyekről, vagy ellenőrizni, hogy a saját webhelyük megfelelően működik-e. Jóval ezután jelentek csak meg a keresőmotorok, és azokban az időkben az internet nagy része elférhetett egy mai számítógép merevlemezén. Az egyetlen igazi problémát akkoriban a forgalom jelentette: az internet-hozzáférés lassú és drága volt mind a honlapot megtekintő személy, mind a tárhelyszolgáltató számára. Ha valaki a saját számítógépén tárolta a weboldalát - ahogyan azt sokan tették -, akkor elég volt néhány túlbuzgó robot és máris elromlottak a dolgok.
1994-ben egy Martijn Koster nevű szoftvermérnök más webes adminisztrátorok és fejlesztők egy csoportjával együtt egy olyan megoldást dolgozott ki, amelyet Robots Exclusion Protocolnak neveztek el. A javaslat elég egyszerű volt: arra kérte a webfejlesztőket, hogy adjanak hozzá egy egyszerű szöveges fájlt a doménjükhöz, amely meghatározza, hogy mely robotok nem vizsgálhatják át az oldalukat, illetve felsorolja azokat az oldalakat, amelyek minden robot számára tiltottak. A robotkészítők számára az alku még egyszerűbb volt: tartsák tiszteletben a szöveges fájl kívánságait.
Koster már a kezdetektől fogva világossá tette, hogy nem gyűlöli a robotokat, és nem is akar megszabadulni tőlük. "A robotok a web azon kevés aspektusai közé tartoznak, amelyek működési problémákat és az embereknek bánatot okoznak" - írta 1994 elején egy WWW-Talk nevű levelezőlistára küldött e-mailjében, amely listán olyan korai internet-pionírok is részt vettek, mint Tim Berners-Lee vagy Marc Andreessen. "Ugyanakkor hasznos szolgáltatásokat nyújtanak." Koster óva intett attól, hogy arról vitatkozzunk, hogy a robotok jók vagy rosszak - ez nem számít, mert léteznek és nem fognak eltűnni. Ő egyszerűen csak egy olyan rendszert próbált megtervezni, amely "minimalizálhatja a problémákat, és talán maximalizálhatja az előnyöket".
Az év nyarára a javaslata szabvány lett - nem hivatalos, de többé-kevésbé általánosan elfogadott. Koster júniusban ismét megkereste a WWW-Talk csoportot egy frissítéssel. "Röviden szólva ez egy olyan módszer, amellyel a robotokat el lehet terelni a webszerver URL-tartományának bizonyos területeitől, egy egyszerű szöveges fájlnak a szerveren való elhelyezésével" - írta. "Ez különösen akkor hasznos, ha nagy archívumokat, hatalmas URL-fákkal rendelkező CGI-szkripteket, ideiglenes információkat tárolsz, vagy egyszerűen csak nem akarsz robotokat kiszolgálni." Létrehozott egy tematikus levelezőlistát, amelynek tagjai megállapodtak az ilyen szövegfájlok néhány alapvető szintaxisában és szerkezetében, és a fájl nevét RobotsNotWanted.txt-ről egyszerű robots.txt-re változtatták. Nagyjából mindenki egyetértett a támogatásában, és a következő 30 év nagy részében ez elég jól működött.
De az internet már nem fér el egy merevlemezen, és a robotok sokkal erősebbek. A Google arra használja őket, hogy a teljes webet feltérképezze és indexelje a keresőmotorja számára, és évente több milliárd dollárt hoz a vállalatnak. A Bing lánctalpasai ugyanezt teszik, a Microsoft pedig más keresőmotoroknak és vállalatoknak licenceli adatbázisát. Az Internet Archive botok segítségével tárolja a weboldalakat az utókor számára. Az Amazon webkúszói termékinformációkat keresve járják az internetet, és egy nemrégiben indított trösztellenes per szerint a vállalat arra használja ezeket az információkat, hogy megbüntesse azokat az eladókat, akik más honlapokon jobb ajánlatokat kínálnak. Az OpenAI-hoz hasonló mesterséges intelligenciával foglalkozó cégek a webet letöltve képeznek ki olyan nagyméretű nyelvi modelleket, amelyek ismét alapvetően megváltoztathatják az információhoz való hozzáférés és az információmegosztás módját.
Az internet letöltésének, tárolásának, rendszerezésének és lekérdezésének képessége minden vállalat vagy fejlesztő számára nagy mennyiségű ismeretet biztosít, amellyel dolgozhat. Az elmúlt egy évben az olyan mesterséges intelligencia termékek, mint a ChatGPT, és az ezek alapjául szolgáló nagyméretű nyelvi modellek elterjedése a kiváló minőségű képzési adatokat az internet egyik legértékesebb árucikkévé tette. Ez arra késztette a különböző internetszolgáltatókat, hogy újragondolják a szervereiken tárolt adatok értékét, és újragondolják, hogy ki mihez férhet hozzá. Ha túlságosan megengedő vagy, akkor a weboldalad elveszítheti minden értékét; ha túlságosan korlátozó vagy, akkor láthatatlanná válhatsz.
Sokféle internetes robot van. Egy teljesen ártatlan robot körbemászik, és ellenőrzi, hogy az oldalon található linkek továbbra is más élő oldalakra vezetnek-e. Egy sokkal okosabb verzió minden e-mail címet és telefonszámot begyűjt, amit csak talál. A legelterjedtebb és jelenleg legvitatottabb azonban egy egyszerű webkúszó, amelynek feladata, hogy az internet minél nagyobb részét megtalálja és letöltse, amit csak tud.
A webkúszók általában meglehetősen egyszerűek. Egy jól ismert weboldalon kezdik, mint például a wikipedia.org vagy egy neves híroldal. A lánctalpas letölti ezt az első oldalt, és elraktározza valahol, majd automatikusan rákattint minden linkre azon az oldalon, letölti az összeset, rákattint az összes linkre mindegyikben, és így terjeszkedik a weben. Elegendő idővel és elegendő számítási erőforrással végül több milliárd weboldalt talál és tölt le. A kompromisszum meglehetősen egyszerű: ha a Google be tudja járni az oldaladat, akkor indexelni is tudja, és megjelenítheti a keresési eredmények között.
A Google 2019-es becslése szerint több mint 500 millió weboldalon volt robots.txt oldal, amely megszabja, hogy ezek a botok hozzáférhetnek-e és mihez. Ezeknek az oldalaknak a felépítése általában nagyjából ugyanaz: megnevezi a "User-agent" nevet, amely a bot nevére utal, amikor azonosítják magukat egy szervernél. A Google ügynöke a Googlebot; az Amazoné az Amazonbot; a Bingé a Bingbot; az OpenAI-é a GPTBot. A Pinterest, a LinkedIn, a Twitter és sok más webhely és szolgáltatás rendelkezik saját botokkal, amelyek közül nem mindegyik kerül megemlítésre minden oldalon. (A Wikipedia és a Facebook két olyan platform, ahol különösen alapos a robotok felsorolása.) A robots.txt oldal felsorolja a webhely azon részeit vagy oldalait, amelyekhez az adott ügynök nem férhet hozzá, valamint a megengedett kivételeket. Ha a sorban csak annyi áll, hogy "Letiltás: /", akkor a bot nem szívesen látott felhasználó.
Régen volt már, hogy egy szerver túlterhelése valós probléma legyen. "Manapság általában kevésbé a weboldalon használt erőforrásokról, és inkább a személyes preferenciákról van szó" - mondja John Mueller, a Google keresési tanácsadója. "Mit szeretnél, hogy feltérképezzenek, indexeljenek és miegymás?". A legnagyobb kérdés, amelyre a legtöbb webhelytulajdonosnak a múltban választ kellett adnia az volt, hogy engedélyezzék-e a Googlebotnak, hogy feltérképezze webhelyüket. (Az, hogy a Google hogyan és hol jeleníti meg az oldalt a keresési eredményekben, természetesen teljesen más tészta). A kérdés az, hogy hajlandó vagy-e hagyni, hogy a Google felfalja a sávszélességed egy részét, és letöltse az oldalad egy példányát a kereséssel járó láthatóságért cserébe.
A Google segít a botja lelassításában, hogy ne terhelje túl a webszervert
A legtöbb weboldal számára ez egyértelmű üzlet volt. "A Google a legfontosabb pókunk" - mondja Tony Stubblebine, a Medium vezérigazgatója. A Google letöltheti a Medium összes oldalát, "cserébe pedig jelentős mennyiségű forgalmat kapunk. Mindenki nyer. Mindenki így gondolja". Ez az az alku, amit a Google az internet egészével kötött, hogy a forgalmat más weboldalakra irányítja, miközben hirdetéseket ad el a keresési eredmények ellenében. És a Google minden jel szerint jó polgára volt a robots.txt-nek. "Nagyjából az összes ismert keresőmotor megfelel ennek" - mondja a Google munkatársa, Mueller. "Örülnek, hogy képesek feltérképezni a webet, de nem akarják bosszantani vele az embereket. Megkönnyíti mindenki életét".
Az elmúlt egy évben azonban a mesterséges intelligencia térnyerése felborította ezt az egyenletet. Sok kiadó és platform számára az, hogy az adataikat a képzési adatokért feltérképezik, kevésbé tűnt kereskedésnek, mint inkább lopásnak. "Az MI-vállalatokkal kapcsolatban elég hamar rájöttünk," mondja Stubblebine, "hogy ez nem csak, hogy nem értékcsere, de egyáltalán nem kapunk érte cserébe semmit. Szó szerint nullát." Amikor Stubblebine tavaly ősszel bejelentette, hogy a Medium blokkolni fogja a mesterséges intelligencia botokat, azt írta, hogy "a mesterséges intelligenciával foglalkozó cégek értéket szívnak ki, hogy az internetes olvasókat spameljék".
Az elmúlt egy évben a médiaipar nagy része csatlakozott Stubblebine véleményéhez. "Nem hisszük, hogy a BBC adatainak jelenlegi, engedélyünk nélküli letöltése az MI modellek képzése érdekében közérdekű" - írta tavaly ősszel a BBC külföldért felelős igazgatója, Rhodri Talfan Davies, aki bejelentette, hogy a BBC is blokkolni fogja az OpenAI botját. A New York Times is blokkolta a GPTBotot, hónapokkal azelőtt, hogy pert indított volna az OpenAI ellen, azt állítva, hogy az OpenAI modelljeit "a The Times több millió, szerzői jogvédelem alatt álló hírcikkének, mélyreható nyomozásának, véleménycikkeinek, ismertetőinek, útmutatóinak és egyéb cikkeinek másolásával és felhasználásával építették fel". Ben Welsh, a Reuters híralkalmazások szerkesztője által készített tanulmány szerint a megkérdezett 1156 kiadóból 606 blokkolta a GPTBotot a robots.txt fájljában.
Nem csak a kiadókról van szó. Az Amazon, a Facebook, a Pinterest, a WikiHow, a WebMD és számos más platform kifejezetten blokkolja a GPTBot hozzáférését néhány vagy az összes weboldalukhoz. A legtöbb ilyen robots.txt oldalon az OpenAI GPTBotja az egyetlen olyan bot, amelyet kifejezetten és teljes mértékben tiltanak. De rengeteg más MI-specifikus bot is elkezdte feltérképezni a webet, mint például az Anthropic anthropic-ai és a Google-Extended. Az Originality.AI tavaly őszi tanulmánya szerint a világháló 1000 legjobb webhelye közül 306 blokkolta a GPTBotot, de csak 85 blokkolta a Google-Extendedet és 28 az anthropic-ai-t.
Vannak olyan botok, amelyeket mind a webes kereséshez, mind a mesterséges intelligenciához használnak. A Common Crawl nevű szervezet által működtetett CCBot keresőmotoros célokra pásztázza a webet, de adatait az OpenAI, a Google és mások is használják modelljeik betanításához. A Microsoft Bingbotja egyszerre kereső és MI-kúszó. És ezek csak azok a botok, amelyek azonosítják magukat - sokan mások viszonylag titokban próbálnak működni, így nehéz őket megállítani vagy egyáltalán megtalálni a többi webes forgalom tengerében. Bármelyik kellően népszerű weboldal esetében a sunyi botok megtalálása tű a szénakazalban probléma.
A GPTBot nagyrészt azért vált a robots.txt fő gonosztevőjévé, mert az OpenAI lehetővé tette, hogy ez megtörténjen. A vállalat közzétett egy oldalt arról, hogyan lehet blokkolni a GPTBotot, és úgy építette fel a botját, hogy minden alkalommal, amikor megközelít egy webhelyet, hangosan azonosítja magát. Természetesen mindezt azután tette, hogy kiképezte a mögöttes modelleket, amelyek ilyen erőssé tették, és csak azután, hogy a technológiai ökoszisztéma fontos részévé vált. De az OpenAI stratégiai vezetője, Jason Kwon szerint ez a lényeg. "Mi egy ökoszisztéma szereplői vagyunk" - mondja. "Ha ebben az ökoszisztémában nyílt módon akarunk részt venni, akkor ez a kölcsönös kereskedelem, ami mindenkit érdekel". Szerinte e kereskedelem nélkül a web elkezd visszahúzódni, bezárulni - és ez rossz az OpenAI-nak és mindenkinek. "Mindezt azért csináljuk, hogy a web nyitott maradhasson".
Alapértelmezés szerint a botkizárási protokoll mindig is megengedő volt. Koster 30 évvel ezelőtt úgy vélte, hogy a legtöbb robot jó, és jó emberek készítik, ezért alapértelmezésben engedélyezi őket. Ez nagyjából helyes döntés volt. "Szerintem az internet alapvetően egy szociális lény" - mondja az OpenAI-s Kwon - "és úgy tűnik, hogy ez a sok évtizeden át tartó üzlet bevált". Szerinte az OpenAI szerepe ennek a megállapodásnak a betartásában az, hogy a ChatGPT a legtöbb felhasználó számára ingyenes maradjon - így visszaadva ezt az értéket -, és tiszteletben tartsa a robotok szabályait. A robots.txt azonban nem jogi dokumentum - és 30 évvel a létrehozása után még mindig az összes érintett fél jóindulatán múlik.
A robotok letiltása a robots.txt oldalon olyan, mint egy "Belépni tilos" tábla kirakása - üzenetet küld, de a bíróságon nem fog megállni. Bármely bot, amely figyelmen kívül akarja hagyni a robots.txt-t, egyszerűen megteheti, és nem kell tartania a következményektől. Az Internet Archive például 2017-ben egyszerűen bejelentette, hogy többé nem tartja be a robots.txt szabályait. "Idővel megfigyeltük, hogy a keresőmotorok botjait célzó robots.txt fájlok nem feltétlenül szolgálják az archiválási céljainkat" - írta akkor Mark Graham, az Internet Archive Wayback Machine igazgatója. És ennyi volt.
Ahogy az MI-vállalatok tovább szaporodnak, és a botok egyre gátlástalanabbá válnak, mindenkinek, aki ki akarja várni az MI korszak eljövetelét, egy végtelen játékban kell részt vennie. Minden egyes robotot külön-külön meg kell állítania, ha ez egyáltalán lehetséges, miközben számolnia kell a mellékhatásokkal is. Ha az MI valóban a keresés jövője - ahogyan azt a Google és mások megjósolták - akkor az MI-botok blokkolása rövid távon győzelmet, hosszú távon azonban katasztrófát jelenthet.
Mindkét oldalon vannak olyanok, akik szerint jobb, erősebb és merevebb eszközökre van szükség a botok kezelésére. Azzal érvelnek, hogy túl sok pénz forog kockán, és túl sok új és szabályozatlan felhasználási eset van ahhoz, hogy arra hagyatkozhassunk, hogy mindenki csak úgy beleegyezik, hogy helyesen cselekszik. "Bár sok szereplőnek van némi önszabályozó mechanizmusa a botok használatára" - írta két, a technológiával foglalkozó ügyvéd a webes lánctalpasok jogszerűségéről szóló 2019-es tanulmányában -, "a szabályok összességében túl gyengék, és túl nehéz őket kikényszeríteni".
Egyes kiadók részletesebb ellenőrzést szeretnének mind a feltérképezés, mind a felhasználás tekintetében, a robots.txt általános igen-vagy-nem engedélyek helyett. A Google néhány évvel ezelőtt erőfeszítéseket tett annak érdekében, hogy a Robots Exclusion Protocol hivatalos, formalizált szabvány legyen, és szintén a robots.txt visszaszorítását szorgalmazta, arra hivatkozva, hogy ez egy régi szabvány, és túl sok webhely nem figyel oda rá. "A meglévő webes kiadói ellenőrzések az új mesterséges intelligencia és kutatási felhasználási esetek előtt kerültek kidolgozásra" - írta tavaly Danielle Romain, a Google bizalomért felelős alelnöke. "Úgy véljük, hogy itt az ideje, hogy a webes és az MI közösségek további gépi olvasású eszközöket vizsgáljanak meg a választás és ellenőrzés érdekében az újonnan megjelenő MI és kutatási felhasználási esetek számára."
Még akkor is, ha a mesterséges intelligenciával foglalkozó vállalatoknak szabályozási és jogi kérdésekkel kell szembenézniük azzal kapcsolatban, hogy hogyan építik fel és képzik ki modelljeiket, ezek a modellek folyamatosan fejlődnek, és úgy tűnik, minden nap új vállalatok indulnak. A kisebb és nagyobb weboldalak döntés előtt állnak: alávetik magukat az MI forradalomnak, vagy ellenállnak neki. Azok számára, akik a kívülállást választják, a legerősebb fegyverük egy három évtizeddel ezelőtti megállapodás, amelyet a világháló néhány legelső és legoptimistább hívője kötött. Ők hittek abban, hogy az internet egy jó hely, tele jó emberekkel, akik mindenekelőtt azt akarták, hogy az internet jó dolog legyen. Abban a világban és az interneten elég volt a vezérléshez, ha egy szöveges fájlban kifejtettük a kívánságainkat. Most, hogy a mesterséges intelligencia újra át fogja alakítani az internet kultúráját és gazdaságát, a szerény, egyszerű szöveges fájl kezd kissé régimódinak tűnni.