SG.hu·
Nem jó debuggolásban az MI

A Microsoft tanulmánya szerint a mesterséges intelligencia modellek még mindig küzdenek a szoftverhibák megtalálásával.
Az OpenAI, az Anthropic és más vezető MI-műhelyek modelljeit egyre gyakrabban használják programozási feladatok segítésére. A Google vezérigazgatója, Sundar Pichai októberben azt mondta, hogy a vállalatnál az új kódok 25%-át mesterséges intelligencia generálja, és a Meta vezérigazgatója, Mark Zuckerberg kifejezte azon törekvését, hogy a közösségi médiaóriáson belül széles körben alkalmazza az MI kódolási modelleket. Mégis, még a legjobb modellek is nehezen javítanak ki olyan szoftverhibákat, amelyeket a tapasztalt fejlesztők rutinból megoldanak.
A Microsoft Research, a cég K+F részlegének új tanulmánya szerint az Anthropic Claude 3.7 Sonnet és az OpenAI o3-mini modellje számos hibát nem tud elhárítani a SWE-bench Lite nevű szoftverfejlesztési tesztben. Az eredmények kijózanítóan emlékeztetnek arra, hogy az OpenAI-hoz hasonló vállalatok merész kijelentései ellenére a mesterséges intelligencia még az olyan területeken, mint a kódolás sem ér fel az emberi szakértőkkel.
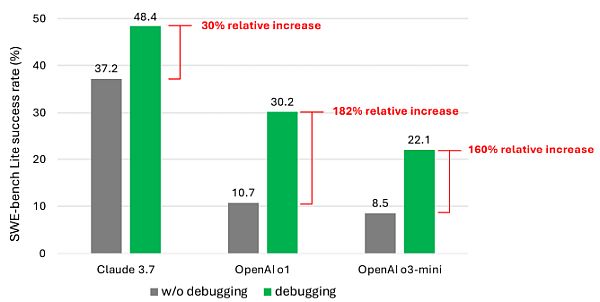
A tanulmány társszerzői kilenc különböző modellt teszteltek egyetlen prompt-alapú ügynök gerinceként, amely számos hibakeresési eszközhöz, köztük egy Python hibakeresőhöz is hozzáférhetett. Ezt az ágenst bízták meg a SWE-bench Lite 300 szoftverhibakeresési feladatokból álló kurátori készlet megoldásával. A társszerzők szerint még erősebb és újabb modellekkel megtámogatva is ritkán sikerült az ügynöküknek a hibakeresési feladatok több mint felét sikeresen megoldania. A Claude 3.7 Sonnet esetében volt a legmagasabb az átlagos sikerességi arány (48,4%), ezt követte az OpenAI o1 (30,2%) és az o3-mini (22,1%).
Miért ez a gyenge teljesítmény? Egyes modellek nehezen tudták használni a rendelkezésükre álló hibakeresési eszközöket, és nehezen értették meg, hogy a különböző eszközök hogyan segíthetnek a különböző problémák megoldásában. A nagyobb probléma azonban a társszerzők szerint az adatok szűkössége volt. Feltételezésük szerint a jelenlegi modellek képzési adatai között nincs elég adat, amely a „szekvenciális döntéshozatali folyamatokat” - vagyis az emberi hibakeresési módszereket - reprezentálná.
„Határozottan hisszük, hogy a modellek képzése vagy finomhangolása jobb interaktív hibakeresővé teheti őket” - írták tanulmányukban a társszerzők. „Ehhez azonban speciális adatokra lesz szükség az ilyen modellképzés teljesítéséhez, például olyan adatokra, amelyek rögzítik a hibakeresővel interakcióba lépő ágenseket, hogy összegyűjtsék a szükséges információkat, mielőtt hibajavítást javasolnának.”
Az eredmények nem éppen sokkolóak. Számos tanulmány kimutatta, hogy a kódgeneráló mesterséges intelligencia hajlamos biztonsági réseket és hibákat bevezetni, olyan területek gyengeségei miatt, mint a programozási logika megértésének hiánya. A Devin nevű népszerű mesterséges intelligencia kódoló eszköz egy nemrégiben végzett értékelés szerint 20 programozási tesztből mindössze hármat tudott teljesíteni.
A Microsoft munkája azonban az egyik legrészletesebb vizsgálat a modellek egyik problémás területére. Valószínűleg nem fogja csökkenteni a befektetők lelkesedését a mesterséges intelligenciával támogatott programozási segédek iránt, de ha szerencsénk van, a fejlesztőket - és felsőbb vezetőiket - kétszer is elgondolkodtatja arról, hogy az MI-re bízzák-e a programozás folyamatát.
Ami azt illeti, egyre több technológiai vezető vitatja azt az elképzelést, hogy az MI automatizálni fogja a kódolási munkákat. A Microsoft társalapítója, Bill Gates azt mondta, hogy szerinte a programozás, mint szakma megmarad. Ugyanígy nyilatkozott Amjad Masad, a Replit vezérigazgatója, Todd McKinnon, az Okta vezérigazgatója és Arvind Krishna, az IBM vezérigazgatója is.
Az OpenAI, az Anthropic és más vezető MI-műhelyek modelljeit egyre gyakrabban használják programozási feladatok segítésére. A Google vezérigazgatója, Sundar Pichai októberben azt mondta, hogy a vállalatnál az új kódok 25%-át mesterséges intelligencia generálja, és a Meta vezérigazgatója, Mark Zuckerberg kifejezte azon törekvését, hogy a közösségi médiaóriáson belül széles körben alkalmazza az MI kódolási modelleket. Mégis, még a legjobb modellek is nehezen javítanak ki olyan szoftverhibákat, amelyeket a tapasztalt fejlesztők rutinból megoldanak.
A Microsoft Research, a cég K+F részlegének új tanulmánya szerint az Anthropic Claude 3.7 Sonnet és az OpenAI o3-mini modellje számos hibát nem tud elhárítani a SWE-bench Lite nevű szoftverfejlesztési tesztben. Az eredmények kijózanítóan emlékeztetnek arra, hogy az OpenAI-hoz hasonló vállalatok merész kijelentései ellenére a mesterséges intelligencia még az olyan területeken, mint a kódolás sem ér fel az emberi szakértőkkel.
?? Mark Zuckerberg on the Joe Rogan podcast
— Haider. (@slow_developer) January 10, 2025
in 2025, AI systems at Meta and other companies will be capable of writing code like mid-level engineers.
at first, it's costly, but the systems will become more efficient as time passes.
eventually, AI engineers will build most of… pic.twitter.com/iJtJqgXm19
A tanulmány társszerzői kilenc különböző modellt teszteltek egyetlen prompt-alapú ügynök gerinceként, amely számos hibakeresési eszközhöz, köztük egy Python hibakeresőhöz is hozzáférhetett. Ezt az ágenst bízták meg a SWE-bench Lite 300 szoftverhibakeresési feladatokból álló kurátori készlet megoldásával. A társszerzők szerint még erősebb és újabb modellekkel megtámogatva is ritkán sikerült az ügynöküknek a hibakeresési feladatok több mint felét sikeresen megoldania. A Claude 3.7 Sonnet esetében volt a legmagasabb az átlagos sikerességi arány (48,4%), ezt követte az OpenAI o1 (30,2%) és az o3-mini (22,1%).
Miért ez a gyenge teljesítmény? Egyes modellek nehezen tudták használni a rendelkezésükre álló hibakeresési eszközöket, és nehezen értették meg, hogy a különböző eszközök hogyan segíthetnek a különböző problémák megoldásában. A nagyobb probléma azonban a társszerzők szerint az adatok szűkössége volt. Feltételezésük szerint a jelenlegi modellek képzési adatai között nincs elég adat, amely a „szekvenciális döntéshozatali folyamatokat” - vagyis az emberi hibakeresési módszereket - reprezentálná.
„Határozottan hisszük, hogy a modellek képzése vagy finomhangolása jobb interaktív hibakeresővé teheti őket” - írták tanulmányukban a társszerzők. „Ehhez azonban speciális adatokra lesz szükség az ilyen modellképzés teljesítéséhez, például olyan adatokra, amelyek rögzítik a hibakeresővel interakcióba lépő ágenseket, hogy összegyűjtsék a szükséges információkat, mielőtt hibajavítást javasolnának.”
Az eredmények nem éppen sokkolóak. Számos tanulmány kimutatta, hogy a kódgeneráló mesterséges intelligencia hajlamos biztonsági réseket és hibákat bevezetni, olyan területek gyengeségei miatt, mint a programozási logika megértésének hiánya. A Devin nevű népszerű mesterséges intelligencia kódoló eszköz egy nemrégiben végzett értékelés szerint 20 programozási tesztből mindössze hármat tudott teljesíteni.
A Microsoft munkája azonban az egyik legrészletesebb vizsgálat a modellek egyik problémás területére. Valószínűleg nem fogja csökkenteni a befektetők lelkesedését a mesterséges intelligenciával támogatott programozási segédek iránt, de ha szerencsénk van, a fejlesztőket - és felsőbb vezetőiket - kétszer is elgondolkodtatja arról, hogy az MI-re bízzák-e a programozás folyamatát.
Ami azt illeti, egyre több technológiai vezető vitatja azt az elképzelést, hogy az MI automatizálni fogja a kódolási munkákat. A Microsoft társalapítója, Bill Gates azt mondta, hogy szerinte a programozás, mint szakma megmarad. Ugyanígy nyilatkozott Amjad Masad, a Replit vezérigazgatója, Todd McKinnon, az Okta vezérigazgatója és Arvind Krishna, az IBM vezérigazgatója is.