SG.hu·
Megbuktak az EU tesztjén a legnagyobb MI-modellek

A legismertebb mesterséges intelligencia modellek némelyike nem felel meg az európai szabályozásnak olyan kulcsfontosságú területeken, mint a kiberbiztonsági ellenálló képesség és a diszkriminatív kimenet.
Az EU már évek óta vitázott az új MI-szabályozásról, amikor az OpenAI 2022 végén nyilvánosságra hozta a ChatGPT-t. A rekordméretű népszerűsége alapvetően felborította a terveket, mert az ilyen modellek állítólagos egzisztenciális kockázatairól szóló nyilvános vita arra ösztönözte a jogalkotókat, hogy külön szabályokat dolgozzanak ki az „általános célú” mesterséges intelligenciákra (GPAI) vonatkozóan. Most egy új, az Európai Unió tisztviselői által is üdvözölt új eszköz több tucat kategóriában tesztelte az olyan nagy technológiai cégek, mint a Meta és az OpenAI által kifejlesztett generatív MI-modelleket, összhangban a szervezet széles körű MI-törvényével, amely a következő két év során lépcsőzetesen lép hatályba.
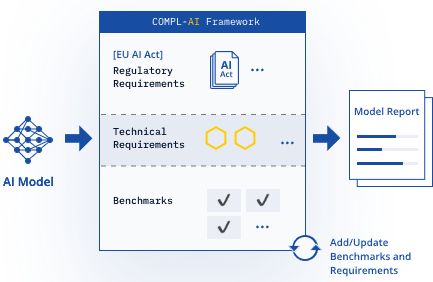
A svájci LatticeFlow MI startup és két kutatóintézetben, az ETH Zürichben és a bolgár INSAIT-ben működő partnerei által tervezett keretrendszer több tucat kategóriában, többek között a technikai robusztusság és a biztonság tekintetében 0 és 1 közötti pontszámot ad az MI-modelleknek. A LatticeFlow által ma közzétett ranglista szerint az Alibaba, az Anthropic, az OpenAI, a Meta és a Mistral által kifejlesztett modellek mind 0,75 vagy annál magasabb átlagpontszámot kaptak. A vállalat „Large Language Model (LLM) Checker” elnevezésű programja azonban feltárta néhány modell hiányosságait a kulcsfontosságú területeken, és rávilágított arra, hogy a vállalatoknak hol kell erőforrásokat átcsoportosítaniuk a megfelelőség biztosítása érdekében.
Az EU jelenleg még mindig azon dolgozik, hogy megállapítsa, hogyan fogja érvényesíteni az MI-törvénynek a generatív MI-eszközökre, például a ChatGPT-re vonatkozó szabályait, ezért szakértőket hívott össze, hogy 2025 tavaszáig kidolgozzák a technológiát szabályozó gyakorlati kódexet. A teszt azonban korai jelzést nyújt azokról a konkrét területekről, ahol a technológiai cégek a törvény megsértését kockáztatják. Például a generatív MI-modellek fejlesztése során állandó probléma volt a diszkriminatív kimenet, amely a nemi, faji és egyéb területeken az emberi előítéleteket tükrözi. A LatticeFlow LLM-ellenőrzője a diszkriminatív kimenetet vizsgálva az OpenAI „GPT-3.5 Turbo” modelljét viszonylag alacsony, 0,46-os pontszámmal értékelte. Ugyanebben a kategóriában az Alibaba Cloud „Qwen1.5 72B Chat” modellje csak 0,37-es értéket kapott.
A „prompt hijacking” tesztelésénél - amely a kibertámadások egy olyan típusa, amikor a hackerek egy rosszindulatú promptot legitimnek álcáznak, hogy érzékeny információkat nyerjenek ki - az LLM Checker a Meta „Llama 2 13B Chat” modelljét 0,42 pontszámmal értékelte. Ugyanebben a kategóriában a francia startup, a Mistral „8x7B Instruct” modellje 0,38 pontot kapott. A Google által támogatott Anthropic által kifejlesztett „Claude 3 Opus” modell kapta a legmagasabb átlagpontszámot, 0,89-et.
A tesztet az MI-törvény szövegével összhangban alakították ki, és azt ki fogják terjeszteni további végrehajtási intézkedésekre, amint azok bevezetésre kerülnek. A LatticeFlow szerint az LLM Checker szabadon elérhető lesz a fejlesztők számára, hogy online tesztelhessék modelljeik megfelelőségét. Petar Tsankov, a cég vezérigazgatója és társalapítója elmondta, hogy a tesztelési eredmények összességében pozitívak voltak, és a vállalatok számára útitervet kínálnak ahhoz, hogy modelljeiket a mesterséges intelligenciáról szóló törvénnyel összhangban finomhangolják. "Az EU még mindig dolgozik az összes megfelelési kritériumon, de már most láthatunk néhány hiányosságot a modellekben” - mondta. „Ha nagyobb hangsúlyt fektetünk a megfelelésre való optimalizálásra, úgy véljük, hogy a modellszolgáltatók jól felkészülhetnek a szabályozási követelmények teljesítésére.”
Bár az Európai Bizottság nem ellenőrizheti a külső eszközöket, a testületet az LLM Checker fejlesztése során végig tájékoztatták, és az az új jogszabályok megvalósításának „első lépéseként” jellemezte azt. Az Európai Bizottság szóvivője elmondta: "A Bizottság üdvözli ezt a tanulmányt és a mesterséges intelligencia-modelleket értékelő platformot, amely az első lépés az EU mesterséges intelligenciáról szóló törvényének technikai követelményekké történő átültetésében.”
Az EU már évek óta vitázott az új MI-szabályozásról, amikor az OpenAI 2022 végén nyilvánosságra hozta a ChatGPT-t. A rekordméretű népszerűsége alapvetően felborította a terveket, mert az ilyen modellek állítólagos egzisztenciális kockázatairól szóló nyilvános vita arra ösztönözte a jogalkotókat, hogy külön szabályokat dolgozzanak ki az „általános célú” mesterséges intelligenciákra (GPAI) vonatkozóan. Most egy új, az Európai Unió tisztviselői által is üdvözölt új eszköz több tucat kategóriában tesztelte az olyan nagy technológiai cégek, mint a Meta és az OpenAI által kifejlesztett generatív MI-modelleket, összhangban a szervezet széles körű MI-törvényével, amely a következő két év során lépcsőzetesen lép hatályba.
A svájci LatticeFlow MI startup és két kutatóintézetben, az ETH Zürichben és a bolgár INSAIT-ben működő partnerei által tervezett keretrendszer több tucat kategóriában, többek között a technikai robusztusság és a biztonság tekintetében 0 és 1 közötti pontszámot ad az MI-modelleknek. A LatticeFlow által ma közzétett ranglista szerint az Alibaba, az Anthropic, az OpenAI, a Meta és a Mistral által kifejlesztett modellek mind 0,75 vagy annál magasabb átlagpontszámot kaptak. A vállalat „Large Language Model (LLM) Checker” elnevezésű programja azonban feltárta néhány modell hiányosságait a kulcsfontosságú területeken, és rávilágított arra, hogy a vállalatoknak hol kell erőforrásokat átcsoportosítaniuk a megfelelőség biztosítása érdekében.
Az EU jelenleg még mindig azon dolgozik, hogy megállapítsa, hogyan fogja érvényesíteni az MI-törvénynek a generatív MI-eszközökre, például a ChatGPT-re vonatkozó szabályait, ezért szakértőket hívott össze, hogy 2025 tavaszáig kidolgozzák a technológiát szabályozó gyakorlati kódexet. A teszt azonban korai jelzést nyújt azokról a konkrét területekről, ahol a technológiai cégek a törvény megsértését kockáztatják. Például a generatív MI-modellek fejlesztése során állandó probléma volt a diszkriminatív kimenet, amely a nemi, faji és egyéb területeken az emberi előítéleteket tükrözi. A LatticeFlow LLM-ellenőrzője a diszkriminatív kimenetet vizsgálva az OpenAI „GPT-3.5 Turbo” modelljét viszonylag alacsony, 0,46-os pontszámmal értékelte. Ugyanebben a kategóriában az Alibaba Cloud „Qwen1.5 72B Chat” modellje csak 0,37-es értéket kapott.
A „prompt hijacking” tesztelésénél - amely a kibertámadások egy olyan típusa, amikor a hackerek egy rosszindulatú promptot legitimnek álcáznak, hogy érzékeny információkat nyerjenek ki - az LLM Checker a Meta „Llama 2 13B Chat” modelljét 0,42 pontszámmal értékelte. Ugyanebben a kategóriában a francia startup, a Mistral „8x7B Instruct” modellje 0,38 pontot kapott. A Google által támogatott Anthropic által kifejlesztett „Claude 3 Opus” modell kapta a legmagasabb átlagpontszámot, 0,89-et.
A tesztet az MI-törvény szövegével összhangban alakították ki, és azt ki fogják terjeszteni további végrehajtási intézkedésekre, amint azok bevezetésre kerülnek. A LatticeFlow szerint az LLM Checker szabadon elérhető lesz a fejlesztők számára, hogy online tesztelhessék modelljeik megfelelőségét. Petar Tsankov, a cég vezérigazgatója és társalapítója elmondta, hogy a tesztelési eredmények összességében pozitívak voltak, és a vállalatok számára útitervet kínálnak ahhoz, hogy modelljeiket a mesterséges intelligenciáról szóló törvénnyel összhangban finomhangolják. "Az EU még mindig dolgozik az összes megfelelési kritériumon, de már most láthatunk néhány hiányosságot a modellekben” - mondta. „Ha nagyobb hangsúlyt fektetünk a megfelelésre való optimalizálásra, úgy véljük, hogy a modellszolgáltatók jól felkészülhetnek a szabályozási követelmények teljesítésére.”
Bár az Európai Bizottság nem ellenőrizheti a külső eszközöket, a testületet az LLM Checker fejlesztése során végig tájékoztatták, és az az új jogszabályok megvalósításának „első lépéseként” jellemezte azt. Az Európai Bizottság szóvivője elmondta: "A Bizottság üdvözli ezt a tanulmányt és a mesterséges intelligencia-modelleket értékelő platformot, amely az első lépés az EU mesterséges intelligenciáról szóló törvényének technikai követelményekké történő átültetésében.”