SG.hu·
Minden eddiginél hatékonyabb rendező algoritmust fejlesztettek

A rendezetlen listák csökkenő vagy növekvő sorrendbe rakásának kódja évtizede változatlan, de a Google DeepMind csoportja most javított rajta.
Bárki, aki vett részt egy alapfokú programozási tanfolyamon, valószínűleg látott már rendezési algoritmust. Ez egy olyan kód, amely egy rendezetlen listában növekvő vagy csökkenő sorrendbe helyezi az elemeket. Ez egy érdekes kihívás, mert nagyon sokféleképpen meg lehet csinálni, rengeteg ember nagyon sok időt töltött már azzal hogy kitalálja, hogyan lehet ezt a rendezést a lehető leghatékonyabban elvégezni. A rendezés annyira alapvető, hogy az algoritmusok a legtöbb programozási nyelv szabványos könyvtáraiba be vannak építve. A C++ könyvtár esetében például ehhez a kódhoz több mint egy évtizede nem nyúltak hozzá.
A Google DeepMind MI-csoportja azonban kifejlesztett egy olyan megerősített tanulási eszközt, amely rendkívül optimalizált algoritmusokat képes kifejleszteni anélkül, hogy először emberi kódpéldákon képeznék ki. A trükk az volt, hogy úgy állították be, hogy a programozást játékként kezelje. A DeepMind arról nevezetes, hogy olyan szoftvert fejlesztett ki, amely megtanítja magát játszani. Ez a megközelítés rendkívül hatékonynak bizonyult, olyan különböző játékokat hódított meg, mint a sakk, a Go vagy a StarCraft. Bár a részletek attól függően változnak, hogy éppen melyik játékkal foglalkozik, a szoftver saját magával játszik, és olyan lehetőségeket fedez fel, amelyekkel maximalizálni tudja a pontszámot. Mivel nem az emberek által játszott játékokon képezték ki, a DeepMind rendszer olyan megközelítéseket fedezhet fel, amelyekre az emberek nem gondoltak. Természetesen, mivel mindig saját maga ellen játszik, vannak olyan esetek, amikor olyan vakfoltokat alakított ki, amelyeket az emberek kihasználhatnak.
Ez a megközelítés nagyon fontos a programozás szempontjából. A nagy nyelvi modellek azért tudnak kódot írni, mert rengeteg emberi példát láttak, de emiatt nem valószínű, hogy olyasmit fejlesztenek ki, amit az emberek korábban még nem csináltak. Ha jól ismert algoritmusokat szeretnénk optimalizálni - mint például a rendezési függvények -, akkor egy meglévő emberi kódra alapozva a legjobb esetben is csak egyenértékű teljesítményt érhetünk el. De hogyan lehet rávenni egy mesterséges intelligenciát, hogy egy valóban új megközelítést találjon? A DeepMind emberei ugyanazt a megközelítést választották, mint a sakk és a Go esetében: a kódoptimalizálást játékká alakították. Az AlphaDev rendszer olyan x86-os assembly algoritmusokat fejlesztett ki, amelyek a kód késleltetését pontszámként kezelték, és megpróbálták minimalizálni ezt a pontszámot, miközben biztosították, hogy a kód hiba nélkül fusson végig. A megerősítő tanulás révén az AlphaDev fokozatosan javította a feszes, nagy hatékonyságú kód írásának képességét. A rendszer saját kódpéldákat generált, majd kiértékelte azokat.
Az összetett programokban történő rendezés nagy és tetszőleges elemgyűjteményeket képes kezelni, ez azonban a szabványos könyvtárak szintjén valójában rendkívül specifikus, csak egy vagy néhány helyzetet kezelő függvények nagy gyűjteményéből épül fel. Például külön algoritmusok léteznek három, négy és öt elem rendezésére. És van egy másik függvénykészlet, amely tetszőleges számú elemet képes kezelni egy határértékig. A DeepMind az AlphaDev-et mindegyik függvényre beállította, de ezek nagyon különbözőképpen működnek. Ennek eredményeképpen a kód teljesítménye általában a szükséges utasítások számával skálázódik. Az AlphaDev képes volt egy-egy utasítást lefaragni a sort-3, sort-5 és sort-8 utasításból, és még többet a sort-6 és sort-7 utasításból. Csak egy olyan utasítás volt (sort-4), ahol nem sikerült javítani az emberi kódon. A kód többszöri futtatása tényleges rendszereken azt mutatta, hogy a kevesebb utasítás valóban jobb teljesítményt eredményezett.
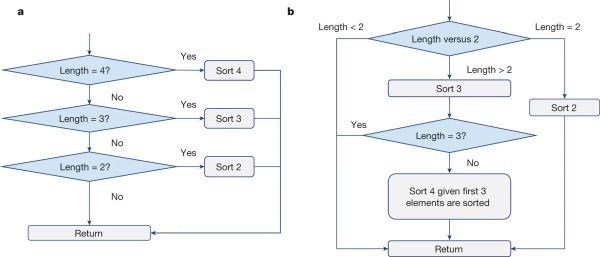
A C++ könyvtár meglévő implementációjában a kód egy sor tesztet végez, hogy megállapítsa, hány elemet kell rendezni, és az adott elemszámhoz hívja meg a dedikált rendezőfüggvényt. Az átdolgozott kód ennél sokkal furcsább dolgot tesz. Megvizsgálja, hogy van-e két elem, és szükség esetén egy külön függvényt hív meg a rendezéshez. Ha kettőnél több elem van, akkor a kód az első három elemet hívja meg a rendezéshez. Ha három elem van, akkor a rendezés eredményét adja vissza. Ha azonban négy elemet kell rendezni, akkor speciális kódot futtat, amely rendkívül hatékonyan beilleszti a negyedik elemet a megfelelő helyre a három rendezett elemből álló halmazon belül. Ez furcsa megközelítésnek tűnik, de következetesen felülmúlta a meglévő kódot.
Mivel az AlphaDev valóban hatékonyabb kódot produkált, a csapat szerette volna ezeket visszavinni a szabványos C++ könyvtárába. A probléma itt az volt, hogy a kód nem C++-ban, hanem assembly-ben készült. Így hát visszafelé kellett dolgozniuk, és ki kellett találniuk azt a C++ kódot, amely ugyanazt az assemblyt eredményezi. Miután ez megtörtént, a kódot beépítették, és ezzel több mint egy évtizede először módosították a kód egy részét. Ennek eredményeként a kutatók becslése szerint az AlphaDev kódját most már naponta trilliószor hajtják végre.
Bárki, aki vett részt egy alapfokú programozási tanfolyamon, valószínűleg látott már rendezési algoritmust. Ez egy olyan kód, amely egy rendezetlen listában növekvő vagy csökkenő sorrendbe helyezi az elemeket. Ez egy érdekes kihívás, mert nagyon sokféleképpen meg lehet csinálni, rengeteg ember nagyon sok időt töltött már azzal hogy kitalálja, hogyan lehet ezt a rendezést a lehető leghatékonyabban elvégezni. A rendezés annyira alapvető, hogy az algoritmusok a legtöbb programozási nyelv szabványos könyvtáraiba be vannak építve. A C++ könyvtár esetében például ehhez a kódhoz több mint egy évtizede nem nyúltak hozzá.
A Google DeepMind MI-csoportja azonban kifejlesztett egy olyan megerősített tanulási eszközt, amely rendkívül optimalizált algoritmusokat képes kifejleszteni anélkül, hogy először emberi kódpéldákon képeznék ki. A trükk az volt, hogy úgy állították be, hogy a programozást játékként kezelje. A DeepMind arról nevezetes, hogy olyan szoftvert fejlesztett ki, amely megtanítja magát játszani. Ez a megközelítés rendkívül hatékonynak bizonyult, olyan különböző játékokat hódított meg, mint a sakk, a Go vagy a StarCraft. Bár a részletek attól függően változnak, hogy éppen melyik játékkal foglalkozik, a szoftver saját magával játszik, és olyan lehetőségeket fedez fel, amelyekkel maximalizálni tudja a pontszámot. Mivel nem az emberek által játszott játékokon képezték ki, a DeepMind rendszer olyan megközelítéseket fedezhet fel, amelyekre az emberek nem gondoltak. Természetesen, mivel mindig saját maga ellen játszik, vannak olyan esetek, amikor olyan vakfoltokat alakított ki, amelyeket az emberek kihasználhatnak.
Ez a megközelítés nagyon fontos a programozás szempontjából. A nagy nyelvi modellek azért tudnak kódot írni, mert rengeteg emberi példát láttak, de emiatt nem valószínű, hogy olyasmit fejlesztenek ki, amit az emberek korábban még nem csináltak. Ha jól ismert algoritmusokat szeretnénk optimalizálni - mint például a rendezési függvények -, akkor egy meglévő emberi kódra alapozva a legjobb esetben is csak egyenértékű teljesítményt érhetünk el. De hogyan lehet rávenni egy mesterséges intelligenciát, hogy egy valóban új megközelítést találjon? A DeepMind emberei ugyanazt a megközelítést választották, mint a sakk és a Go esetében: a kódoptimalizálást játékká alakították. Az AlphaDev rendszer olyan x86-os assembly algoritmusokat fejlesztett ki, amelyek a kód késleltetését pontszámként kezelték, és megpróbálták minimalizálni ezt a pontszámot, miközben biztosították, hogy a kód hiba nélkül fusson végig. A megerősítő tanulás révén az AlphaDev fokozatosan javította a feszes, nagy hatékonyságú kód írásának képességét. A rendszer saját kódpéldákat generált, majd kiértékelte azokat.
Az összetett programokban történő rendezés nagy és tetszőleges elemgyűjteményeket képes kezelni, ez azonban a szabványos könyvtárak szintjén valójában rendkívül specifikus, csak egy vagy néhány helyzetet kezelő függvények nagy gyűjteményéből épül fel. Például külön algoritmusok léteznek három, négy és öt elem rendezésére. És van egy másik függvénykészlet, amely tetszőleges számú elemet képes kezelni egy határértékig. A DeepMind az AlphaDev-et mindegyik függvényre beállította, de ezek nagyon különbözőképpen működnek. Ennek eredményeképpen a kód teljesítménye általában a szükséges utasítások számával skálázódik. Az AlphaDev képes volt egy-egy utasítást lefaragni a sort-3, sort-5 és sort-8 utasításból, és még többet a sort-6 és sort-7 utasításból. Csak egy olyan utasítás volt (sort-4), ahol nem sikerült javítani az emberi kódon. A kód többszöri futtatása tényleges rendszereken azt mutatta, hogy a kevesebb utasítás valóban jobb teljesítményt eredményezett.
A C++ könyvtár meglévő implementációjában a kód egy sor tesztet végez, hogy megállapítsa, hány elemet kell rendezni, és az adott elemszámhoz hívja meg a dedikált rendezőfüggvényt. Az átdolgozott kód ennél sokkal furcsább dolgot tesz. Megvizsgálja, hogy van-e két elem, és szükség esetén egy külön függvényt hív meg a rendezéshez. Ha kettőnél több elem van, akkor a kód az első három elemet hívja meg a rendezéshez. Ha három elem van, akkor a rendezés eredményét adja vissza. Ha azonban négy elemet kell rendezni, akkor speciális kódot futtat, amely rendkívül hatékonyan beilleszti a negyedik elemet a megfelelő helyre a három rendezett elemből álló halmazon belül. Ez furcsa megközelítésnek tűnik, de következetesen felülmúlta a meglévő kódot.
Mivel az AlphaDev valóban hatékonyabb kódot produkált, a csapat szerette volna ezeket visszavinni a szabványos C++ könyvtárába. A probléma itt az volt, hogy a kód nem C++-ban, hanem assembly-ben készült. Így hát visszafelé kellett dolgozniuk, és ki kellett találniuk azt a C++ kódot, amely ugyanazt az assemblyt eredményezi. Miután ez megtörtént, a kódot beépítették, és ezzel több mint egy évtizede először módosították a kód egy részét. Ennek eredményeként a kutatók becslése szerint az AlphaDev kódját most már naponta trilliószor hajtják végre.