SG.hu·
Az MI-tesztek többsége hülyeséget mér

A benchmarkok manipulálhatók, torz mintákat használnak, és a cégek sokkal inkább marketingeszközként kezelik őket, mint a valós fejlődés jellemzésére.
A mesterséges intelligencia iparág egyik kedvenc mutatószáma a benchmark-eredmény: a cégek büszkén kommunikálják, milyen jól teljesítenek a modellek különféle teszteken, a sajtó és a befektetők pedig ezeket az eredményeket gyakran készpénzként kezelik. Egy friss, több egyetemi és kutatóintézeti szerzőkből álló tanulmány azonban éles figyelmeztetést fogalmaz meg: a mostani gyakorlat sok helyen tudományos szempontból gyenge lábakon áll, és a mérések többsége nem azt méri, amit ígér. Az Oxford Internet Institute (OII) és társ-szerzői által készített áttekintés 445 nagy nyelvi modell (LLM) benchmarkot vizsgált meg, és ezekből mindössze 16 százalék alkalmazott kellően szigorú módszertant, miközben körülbelül a tesztek fele olyan absztrakt fogalmakat - például „érvelést” vagy „ártatlanságot” - állít mérni, amelyekről nem adnak világos definíciót.
A probléma nem csupán elméleti: a benchmarkokból származó számok alapozzák meg azt a narratívát, hogy egy modell jól teljesít egy adott feladattípus megoldásánál, és ez hatással van a befektetői hangulatra, a piaci konkurenciára és a szabályozói figyelemre. Amikor például az OpenAI bemutatta a GPT-5-öt, a cég kiemelkedő teljesítményt tett közzé bizonyos benchmarkokon (AIME 2025, SWE-bench Verified, Aider Polyglot, MMMU, HealthBench Hard), és ezeket az eredményeket használta kommunikációs és termékpozicionálási célokra. A probléma az, hogy ha maga a benchmark hibásan van felépítve, vagy a különböző szereplők nem ugyanazt mérik ugyanúgy, az összehasonlítás értelmetlenné válik.
A tanulmány részletesen felhívja a figyelmet több, gyakran előforduló hibára. Az egyik ilyen a mintavétel gyengesége: a kutatás szerint a benchmarkok 27 százaléka „kényelmi mintavételt” alkalmazott, vagyis olyan adathalmazon tesztelt, amelyet egyszerű volt összeszedni, de nem reprezentálja a valós feladatok sokszínűségét. Ennek szemléletes példáját adja a matematikai AIME-teszt: ha egy benchmark kizárólag ilyen, kifejezetten „kis számokra” tervezett feladatokból áll, akkor egy jó teljesítmény ezen a készleten nem jó indikátora a modell nagy számokkal, bonyolultabb számtani problémákkal vagy valódi világban előforduló számítási kihívásokkal szembeni képességeinek. Másik gond, hogy sok benchmark konstrukcionális érvényessége (construct validity) kérdéses: a teszt ígérhet „jó érvelést” vagy „biztonságosságot”, de nem definiálja egyértelműen, mit ért ezek alatt, és hogyan ellenőrzi, hogy a modell valóban azt a képességet használta, amit állítanak.
A mérési problémákhoz társul a benchmarkok könnyű kontaminálhatósága (beszennyeződhetősége): ha a tesztkészleten szereplő példák valamilyen formában bekerülnek a modell tanítókészletébe, akkor a magas pontszám nem a valódi általánosító képességet mutatja, hanem a memóriát vagy „saját anyag újraprezentálását”. Ezen túlmenően a kutatók rámutatnak a prompting és értékelési eljárások heterogenitására: különböző csapatok eltérő promptokkal és post-processing módszerekkel futtathatják ugyanazt a modellt, így a közzétett számok nem összevethetők.
Az iparágban ráadásul erős gazdasági ösztönzők is működnek a benchmarkok „megjavítására” vagy optimalizálására: a jobb eredmények magasabb marketingértéket teremtenek, ezért a modellezők hajlamosak a tesztekre hangolni rendszereiket, olykor akár olyan trükkökkel, amelyek nem jelentenek a elméletű jellegű fejlődést, csak a teszt végrehajtását.
A kutatók nem csupán a kritikát fogalmazták meg, hanem konkrét javaslatokat is tettek. Nyolc fő ajánlást soroltak fel, amelyek célja a benchmarkok konstruktív érvényességének és reprodukálhatóságának javítása. Ezek közé tartozik a mérendő jelenségek egyértelmű meghatározása (pl. pontosan mit értünk „érvelés” alatt), a kontamináció elkerülésére való felkészülés (pl. zárolt, publikus forrásoktól független tesztkészletek), statisztikai összehasonlító módszerek alkalmazása (például megfelelő hibasávok és tesztek használata a modellek közti különbség megbízható kimutatására), valamint a protokollok, promptok és értékelő szkriptek teljes körű publikálása. A cél, hogy a benchmark ne csupán papíron mutasson előrelépést, hanem valódi, reprodukálható és általánosítható fejlődést jelezzen a modellek képességeiben.
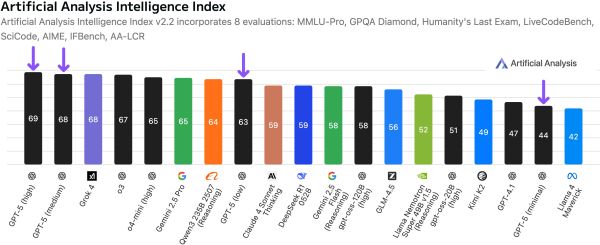
A probléma nem újkeletű: a kutatócsoport által hivatkozott korábbi áttekintés - amelyet az Európai Bizottság Közös Kutatóközpontja publikált - már februárban felsorolt a benchmarkokkal kapcsolatos rendszerhibákat, többek között a mérési célok és módszerek torzulását, a „játékos” optimalizációt és az ismeretlen kockázatokat. Ezzel párhuzamosan egyes független kezdeményezések is születtek: az ARC-AGI benchmarkot adminisztráló Arc Prize Foundation elnöke bejelentett egy „ARC Prize Verified” programot, amelynek célja a legerősebb rendszerek értékelésének nagyobb szigorúsága és összehasonlíthatósága például egységesebb protokollok és hitelesítő eljárások bevezetésével.
A benchmarkok megbízhatatlansága súlyos következményekkel jár. Ha a mérések torzítanak, a döntéshozók téves következtetéseket hozhatnak a technológia érettségéről; a befektetők feleslegesen magas értékelést adhatnak egy vállalkozásnak; a szabályozók rossz alapokra helyezhetik a politikákat; és a fogyasztók vagy ügyfelek tévesen bízhatnak egy rendszer képességeiben. Ez különösen érzékeny terület az úgynevezett biztonsági és ártalomcsökkentési (harmlessness) értékeléseknél: ha ennek mérésére nem létezik közmegegyezés, akkor a „biztonságosnak” kommunikált rendszer akár veszélyes döntéseket is hozhat, vagy nem képes elkerülni a károkat.
A benchmarkokkal kapcsolatos vitát tovább árnyalja az AGI-kérdés, azaz az általános mesterséges intelligencia létrejötte. Az OpenAI és Microsoft belső kritériumokat alkottak meg annak kimondására, mikor érkezik el az AGI pillanata, ami a vállalatok érdeke szerint nem feltétlenül pusztán kognitív teljesítmény, hanem gazdasági mérőszámokkal is összefügghet. Egy belső mérő lehet az, hogy az MI-rendszer legalább 100 milliárd dollár profitot generáljon; vagyis pénzt mérnek, mert a bevétel és profit sokkal könnyebben számszerűsíthető, mint az intelligencia absztrakt fogalma. Ez a megközelítés rámutat egy alapvető paradoxonra: a pénzügyi célok mérése egyszerűbb és közvetlenebb, de nem feltétlenül ad információt a rendszer kognitív vagy biztonsági tulajdonságairól.
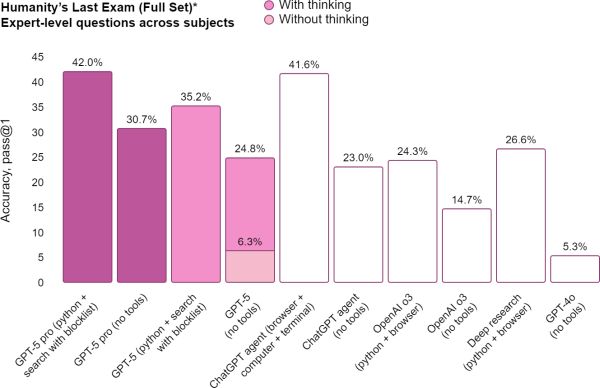
Mit tehetnek a szereplők, ha nem akarják, hogy a benchmarkok kijátsszák őket? A kutatók javaslatai mellett célszerű néhány gyakorlati lépést meghozni. A benchmarkok készítőinek előregondolkodással, közösségi bevonással és független auditálással kell dolgozniuk; a modelleket tesztelőknek nyilvános protokollokat, prompt- és értékelési scripteket kell publikálniuk; támogatniuk kell a független harmadik fél által végzett reprodukciót és verifikációt; a promptok és tesztek különböző variánsainak szerepeltetésével érdemes vizsgálni a robusztusságot; és a statisztikai szignifikancia mellett a gyakorlati jelentőséget is mérlegelni kell, tehát nem elég a százalékos javulás, látni kell azt is, mit jelent ez a valós alkalmazásokban. Emellett a szabályozóknak érdemes iránymutatást adniuk a benchmark-közleményekre és a marketingben való felhasználásukra vonatkozóan, hogy a közönség ne tévesszen össze egy "jó teszteredményt” egy valódi, minden körülmények között megbízható képességgel.
A mesterséges intelligencia gyors fejlődése és a verseny ösztönző ereje miatt nem várható a benchmarkok halála, ezért inkább a gyakorlat javítására, standardizálására és átláthatóságának növelésére van szükség. A mostani kritika és a közzétett ajánlások jó alapot adhatnak ahhoz, hogy a piac a valódi előrelépéseket jobban meg tudja különböztetni a teszthalmazon való „játékoktól”. Ha ez nem történik meg, a legnagyobb nyertesek paradox módon pont azok lehetnek, akik a benchmarkrendszert a saját marketing- és üzleti érdekeik szerint manipulálni tudják, miközben a felhasználók, a szabályozók és a tudományos közösség kevesebb megbízható információval kénytelen dolgozni.
A benchmarkok jelen formájukban gyakran rossz viccnek tűnnek, de nem a kutatók nevetnek rajta, hanem azok a szereplők, akik a gyenge definíciókat, a szűk mintákat és a heterogén protokollokat képesek a maguk javára fordítani. A megoldás több tudatosságot, jobb módszertant, nyílt protokollokat és független verifikációt igényel, csak így válhatnak a benchmarkok tényleg megbízható mutatószámaivá annak, mikor és hogyan javulnak a mesterséges intelligencia rendszerek valós képességei.
A mesterséges intelligencia iparág egyik kedvenc mutatószáma a benchmark-eredmény: a cégek büszkén kommunikálják, milyen jól teljesítenek a modellek különféle teszteken, a sajtó és a befektetők pedig ezeket az eredményeket gyakran készpénzként kezelik. Egy friss, több egyetemi és kutatóintézeti szerzőkből álló tanulmány azonban éles figyelmeztetést fogalmaz meg: a mostani gyakorlat sok helyen tudományos szempontból gyenge lábakon áll, és a mérések többsége nem azt méri, amit ígér. Az Oxford Internet Institute (OII) és társ-szerzői által készített áttekintés 445 nagy nyelvi modell (LLM) benchmarkot vizsgált meg, és ezekből mindössze 16 százalék alkalmazott kellően szigorú módszertant, miközben körülbelül a tesztek fele olyan absztrakt fogalmakat - például „érvelést” vagy „ártatlanságot” - állít mérni, amelyekről nem adnak világos definíciót.
A probléma nem csupán elméleti: a benchmarkokból származó számok alapozzák meg azt a narratívát, hogy egy modell jól teljesít egy adott feladattípus megoldásánál, és ez hatással van a befektetői hangulatra, a piaci konkurenciára és a szabályozói figyelemre. Amikor például az OpenAI bemutatta a GPT-5-öt, a cég kiemelkedő teljesítményt tett közzé bizonyos benchmarkokon (AIME 2025, SWE-bench Verified, Aider Polyglot, MMMU, HealthBench Hard), és ezeket az eredményeket használta kommunikációs és termékpozicionálási célokra. A probléma az, hogy ha maga a benchmark hibásan van felépítve, vagy a különböző szereplők nem ugyanazt mérik ugyanúgy, az összehasonlítás értelmetlenné válik.
A tanulmány részletesen felhívja a figyelmet több, gyakran előforduló hibára. Az egyik ilyen a mintavétel gyengesége: a kutatás szerint a benchmarkok 27 százaléka „kényelmi mintavételt” alkalmazott, vagyis olyan adathalmazon tesztelt, amelyet egyszerű volt összeszedni, de nem reprezentálja a valós feladatok sokszínűségét. Ennek szemléletes példáját adja a matematikai AIME-teszt: ha egy benchmark kizárólag ilyen, kifejezetten „kis számokra” tervezett feladatokból áll, akkor egy jó teljesítmény ezen a készleten nem jó indikátora a modell nagy számokkal, bonyolultabb számtani problémákkal vagy valódi világban előforduló számítási kihívásokkal szembeni képességeinek. Másik gond, hogy sok benchmark konstrukcionális érvényessége (construct validity) kérdéses: a teszt ígérhet „jó érvelést” vagy „biztonságosságot”, de nem definiálja egyértelműen, mit ért ezek alatt, és hogyan ellenőrzi, hogy a modell valóban azt a képességet használta, amit állítanak.
A mérési problémákhoz társul a benchmarkok könnyű kontaminálhatósága (beszennyeződhetősége): ha a tesztkészleten szereplő példák valamilyen formában bekerülnek a modell tanítókészletébe, akkor a magas pontszám nem a valódi általánosító képességet mutatja, hanem a memóriát vagy „saját anyag újraprezentálását”. Ezen túlmenően a kutatók rámutatnak a prompting és értékelési eljárások heterogenitására: különböző csapatok eltérő promptokkal és post-processing módszerekkel futtathatják ugyanazt a modellt, így a közzétett számok nem összevethetők.
Az iparágban ráadásul erős gazdasági ösztönzők is működnek a benchmarkok „megjavítására” vagy optimalizálására: a jobb eredmények magasabb marketingértéket teremtenek, ezért a modellezők hajlamosak a tesztekre hangolni rendszereiket, olykor akár olyan trükkökkel, amelyek nem jelentenek a elméletű jellegű fejlődést, csak a teszt végrehajtását.
A kutatók nem csupán a kritikát fogalmazták meg, hanem konkrét javaslatokat is tettek. Nyolc fő ajánlást soroltak fel, amelyek célja a benchmarkok konstruktív érvényességének és reprodukálhatóságának javítása. Ezek közé tartozik a mérendő jelenségek egyértelmű meghatározása (pl. pontosan mit értünk „érvelés” alatt), a kontamináció elkerülésére való felkészülés (pl. zárolt, publikus forrásoktól független tesztkészletek), statisztikai összehasonlító módszerek alkalmazása (például megfelelő hibasávok és tesztek használata a modellek közti különbség megbízható kimutatására), valamint a protokollok, promptok és értékelő szkriptek teljes körű publikálása. A cél, hogy a benchmark ne csupán papíron mutasson előrelépést, hanem valódi, reprodukálható és általánosítható fejlődést jelezzen a modellek képességeiben.
A probléma nem újkeletű: a kutatócsoport által hivatkozott korábbi áttekintés - amelyet az Európai Bizottság Közös Kutatóközpontja publikált - már februárban felsorolt a benchmarkokkal kapcsolatos rendszerhibákat, többek között a mérési célok és módszerek torzulását, a „játékos” optimalizációt és az ismeretlen kockázatokat. Ezzel párhuzamosan egyes független kezdeményezések is születtek: az ARC-AGI benchmarkot adminisztráló Arc Prize Foundation elnöke bejelentett egy „ARC Prize Verified” programot, amelynek célja a legerősebb rendszerek értékelésének nagyobb szigorúsága és összehasonlíthatósága például egységesebb protokollok és hitelesítő eljárások bevezetésével.
A benchmarkok megbízhatatlansága súlyos következményekkel jár. Ha a mérések torzítanak, a döntéshozók téves következtetéseket hozhatnak a technológia érettségéről; a befektetők feleslegesen magas értékelést adhatnak egy vállalkozásnak; a szabályozók rossz alapokra helyezhetik a politikákat; és a fogyasztók vagy ügyfelek tévesen bízhatnak egy rendszer képességeiben. Ez különösen érzékeny terület az úgynevezett biztonsági és ártalomcsökkentési (harmlessness) értékeléseknél: ha ennek mérésére nem létezik közmegegyezés, akkor a „biztonságosnak” kommunikált rendszer akár veszélyes döntéseket is hozhat, vagy nem képes elkerülni a károkat.
A benchmarkokkal kapcsolatos vitát tovább árnyalja az AGI-kérdés, azaz az általános mesterséges intelligencia létrejötte. Az OpenAI és Microsoft belső kritériumokat alkottak meg annak kimondására, mikor érkezik el az AGI pillanata, ami a vállalatok érdeke szerint nem feltétlenül pusztán kognitív teljesítmény, hanem gazdasági mérőszámokkal is összefügghet. Egy belső mérő lehet az, hogy az MI-rendszer legalább 100 milliárd dollár profitot generáljon; vagyis pénzt mérnek, mert a bevétel és profit sokkal könnyebben számszerűsíthető, mint az intelligencia absztrakt fogalma. Ez a megközelítés rámutat egy alapvető paradoxonra: a pénzügyi célok mérése egyszerűbb és közvetlenebb, de nem feltétlenül ad információt a rendszer kognitív vagy biztonsági tulajdonságairól.
Mit tehetnek a szereplők, ha nem akarják, hogy a benchmarkok kijátsszák őket? A kutatók javaslatai mellett célszerű néhány gyakorlati lépést meghozni. A benchmarkok készítőinek előregondolkodással, közösségi bevonással és független auditálással kell dolgozniuk; a modelleket tesztelőknek nyilvános protokollokat, prompt- és értékelési scripteket kell publikálniuk; támogatniuk kell a független harmadik fél által végzett reprodukciót és verifikációt; a promptok és tesztek különböző variánsainak szerepeltetésével érdemes vizsgálni a robusztusságot; és a statisztikai szignifikancia mellett a gyakorlati jelentőséget is mérlegelni kell, tehát nem elég a százalékos javulás, látni kell azt is, mit jelent ez a valós alkalmazásokban. Emellett a szabályozóknak érdemes iránymutatást adniuk a benchmark-közleményekre és a marketingben való felhasználásukra vonatkozóan, hogy a közönség ne tévesszen össze egy "jó teszteredményt” egy valódi, minden körülmények között megbízható képességgel.
A mesterséges intelligencia gyors fejlődése és a verseny ösztönző ereje miatt nem várható a benchmarkok halála, ezért inkább a gyakorlat javítására, standardizálására és átláthatóságának növelésére van szükség. A mostani kritika és a közzétett ajánlások jó alapot adhatnak ahhoz, hogy a piac a valódi előrelépéseket jobban meg tudja különböztetni a teszthalmazon való „játékoktól”. Ha ez nem történik meg, a legnagyobb nyertesek paradox módon pont azok lehetnek, akik a benchmarkrendszert a saját marketing- és üzleti érdekeik szerint manipulálni tudják, miközben a felhasználók, a szabályozók és a tudományos közösség kevesebb megbízható információval kénytelen dolgozni.
A benchmarkok jelen formájukban gyakran rossz viccnek tűnnek, de nem a kutatók nevetnek rajta, hanem azok a szereplők, akik a gyenge definíciókat, a szűk mintákat és a heterogén protokollokat képesek a maguk javára fordítani. A megoldás több tudatosságot, jobb módszertant, nyílt protokollokat és független verifikációt igényel, csak így válhatnak a benchmarkok tényleg megbízható mutatószámaivá annak, mikor és hogyan javulnak a mesterséges intelligencia rendszerek valós képességei.