SG.hu·
CAPTCHA - Ha beírja a szót, megkapja
A legtöbb embertől, ha megkérdezik, tudja-e mi az a CAPTCHA, azt mondja nem. Pedig biztos, hogy igen. Mára szinte minden regisztrációt igénylő weboldal használja a képekről leolvasandó betűket, annak ellenőrzésére, hogy a vonal másik végén tényleg egy ember ül és nem egy ügyes program. Mire jó? Hogy működik? Miért nem tudom elolvasni néha én sem a betűket?
Maga a kifejezés a "Completely Automated Public Turing-test to tell Computers and Humans Apart" mozaikszava, ami körülbelül annyit tesz, hogy "teljesen automatizált publikus Turing-teszt a számítógépek és emberek megkülönböztetésére". Az eredetileg a Carnegie Mellon Egyetemen kidolgozott módszer lényege pedig nem több, nem kevesebb, mint egy feladat, melyre a szerver megkéri a felhasználót, hogy oldja meg, végezze el.
A feladatok nem bonyolultak bár sok fórumon biztos jót tenne a színvonalnak, ha egyfajta IQ-tesztként is funkcionálna, de egyszerűen arról van szó, hogy olyan, az emberi agy számára triviális felismerésre kérik a felhasználót, amire a számítógépek egyelőre nem vagy csak nagyon nehezen lennének képesek. A Captcha kapcsán használt Turing-tesztet egyébként fordított Turingnak is becézik, hiszen eredetileg ezt a tesztet arra kreálták, hogy emberek vizsgálják a mesterséges intelligenciát, itt pedig egy számítógép túráztat embereket.
Belépés csak embereknek!
Ennek a tesztnek a manapság is legelterjedtebb formája a kissé eltorzított vagy színes vonalakkal tarkított kép, amelyen betűk és számok szerepelnek. Az ember asszociációs képessége könnyen felismeri, hogy mi a zaj és mi a tartalom, de a legtöbb számítógépes karakterfelismerőt ez már megfekteti. A módszer gyakorlati lényege, hogy az olyan szájtokon, amit emberi léptékekre terveztek, ne szaporodjanak el a scriptek, programok, melyek milliós nagyságrendben képesek percenként ugyanazt megcsinálni, amit egy ember esetleg percenként egyszer, vagy általában csak egyszer csinálna.
A legelső ilyen megoldást a régmúlt egyik internetes keresője, az Altavista használta 1997-ben, hogy elkerülje a webcímek botok általi tömeges hozzáadását a kereső adatbázishoz. A torzított képek kialakításához egy OCR-t, azaz egy szövegfelismerőt használták, megvizsgálták, hogy milyen esetekben hibázik és annak alapján állították össze a mintákat.
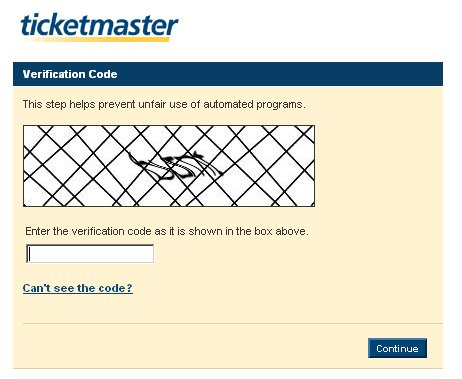
Ezt ismerje fel valaki!
2000 után pedig ennél jóval szélesebb körben kezdték el használni és a módszerek is egyre változatosabbak lettek. Van amikor értelmes szavakat kell bepötyögni, van amikor színes vonalakkal van áthúzgálva a karaktersor és van amikor grafikai torzításon mennek keresztül. Gondolom nem meglepetés, hogy mint mindenhol, itt is versenyfutás van a jó és a rosszfiúk között, hiszen a felismerő programok is egyre fejlettebbé váltak, így a teszteknek is egyre bonyolultabbaknak kellett lennie.
Manapság a legnépszerűbb kijátszása az ilyen rendszereknek egy hibrid megoldás. A számítógép végzi a kulimunkát, de néhány ember ül a gépnél, és amikor a szoftver elér egy CAPTCHA védelemhez, akkor feldobja az embernek az ablakot, aki beírja és máris mehet tovább a móka. Ráadásul elég sok weboldal van, ahol csupán néhány kép vagy néhány karaktersor van, amit később a gép már fel fog ismerni.
A hazai legnagyobb linkgyűjtemény, a Startlap esetén is alig néhány szó pörög körbe, így viszonylag könnyű lenne egy komoly támadás ellenük. A számítógépnek ilyenkor négy lépésen kell túlesnie: Elsőként kiemelni a képfájlt a weboldalról. Ez könnyű. Másodszor izolálni a karaktereket a háttértől, ami lehet zizis, vonalas, színes, csillogós. Ez nehéz. Ha mégis megvan, akkor már csak szegmentálni kell a képet, azaz felszeletelni darabokra betűnként, majd végül felismerni őket egyesével. Ez szintén egyszerű.
Cicás CAPTCHA
A szöveg alapú felismerés a fentiek szerint már szinte a kisujjában van a gépeknek, ezért itt is tovább kell lépni, ahogy a spamküldők is tovább léptek a html-ről a kép alapú kéretlen szemétre. A probléma a képekkel, hogy egy kis szájt nehezen lesz képes összeszedni és működtetni elegendő elemből álló adatbázist, a kevés darab pedig egyszerűen azt jelenti, hogy a gépeknek vagy az őket üzemeltetőknek megéri végigpróbálkozni az összest és rájönni, hogy melyik mit ábrázol. A felhasználóknak viszont ez problémás lehet, mert ha egy macska van a képen, akkor az emberek anyanyelvük és mindenféle egyéb változójuk alapján beírhatják, hogy cat, katze, cica vagy akár azt is, hogy piszimacska.
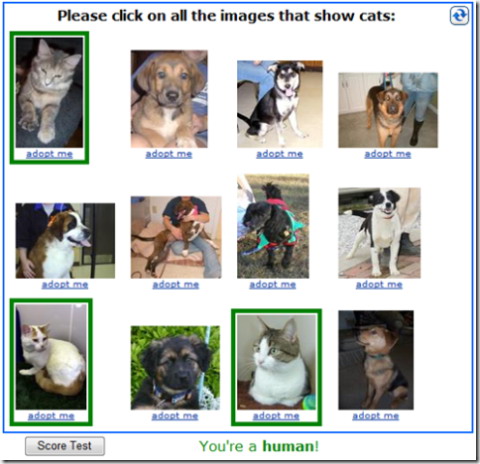 Klikkeljen a cicákra, ha ember!
Klikkeljen a cicákra, ha ember!
Amennyiben az oldal nem szeretné sokkolni a felhasználóit, akkor inkább bináris feladványokat állít fel, tehát jön egy kép és el kell dönteni, hogy ez kutya vagy macska? ló vagy tehén? stb. Egy 16 képből álló adatbázis már 1:65536-ra rontja a gép esélyét hogy eltalálja, mi szerepel a képen (2 a 16. hatványon). A probléma viszont ott kezdődik, hogy szép lassan a gépek is megtanulnak képeket felismerni és akkor lassan ott járunk, hogy egy e-mail regisztrációhoz vissza kell a webkamerába énekelni és táncolni egy teljes folk műsort. A Google szoftverei tökéletesen jó példát adnak, hiszen nemrégiben számoltak be arról, hogy a képkeresőjük képes felismerni ha egy emberi arcot lát a képen. Nyilván egy macskát még könnyebb lenne felismertetni.
A cica témát egyébként a Microsoft dobta be nemrég, aki a spam elkerülése végett ilyen kép alapú felismertetést vezetne be azzal a bónusszal, hogy a képeken lehetőség szerint egy kisebb kivágás vagy egy rosszabb beállítás szerepelne az állatról, néhány olyan jeggyel, amiről biztosan felismeri egy normális ember, hogy milyen állatot lát. A jelenleg folyó béta tesztben 12 kutyát/macskát használnak, ahol sokszor nem is látszik a teljes állat, csak részletek belőle. A projektet pedig el is nevezték szépen Asirrának (Animal Species Image Recognition for Restricting Access / Hozzáférést korlátozó állatfaj-képfelismerés).
Ok - okozat
Biztos sokakban felmerül, hogy vajon miért jó vicc a rosszindulatú programok megalkotóinak átjutni ezeken a regisztrációkon? Ki akar 1 millió e-mail címet regisztrálni, ki akar 1 millió alkalommal hozzáadni egy linket egy keresőhöz? A válasz szinte magától érthetődő. Nem más, mint az internet aljas csúszó-mászói, a kéretlen levelek küldői, a csúf, gonosz spammerek.
Pengeélen táncolnak, mivel egyre jobb védelmek vannak a szemetük kiszűrésére, ezért folyamatosan parazitaként kell megszállniuk a szolgáltatókat. Mára annyira fejlett scriptek léteznek, hogy a blog oldalakra is beregisztrálnak és minden postba beleszemetelnek egy kéretlen reklámot, de a webkettes társadalom többi részére is hányingert hoznak ezek a történések. Persze amíg valaki hajlandó fizetni ezekért a hirdetésekért addig mindig lesz valaki, ahogy valahogyan túljár a védelmek eszén. Amíg pedig lesznek lusták avagy bolondok akik beugranak ezeknek a reklámoknak, addig lesz, aki fizessen érte.
Maga a kifejezés a "Completely Automated Public Turing-test to tell Computers and Humans Apart" mozaikszava, ami körülbelül annyit tesz, hogy "teljesen automatizált publikus Turing-teszt a számítógépek és emberek megkülönböztetésére". Az eredetileg a Carnegie Mellon Egyetemen kidolgozott módszer lényege pedig nem több, nem kevesebb, mint egy feladat, melyre a szerver megkéri a felhasználót, hogy oldja meg, végezze el.
A feladatok nem bonyolultak bár sok fórumon biztos jót tenne a színvonalnak, ha egyfajta IQ-tesztként is funkcionálna, de egyszerűen arról van szó, hogy olyan, az emberi agy számára triviális felismerésre kérik a felhasználót, amire a számítógépek egyelőre nem vagy csak nagyon nehezen lennének képesek. A Captcha kapcsán használt Turing-tesztet egyébként fordított Turingnak is becézik, hiszen eredetileg ezt a tesztet arra kreálták, hogy emberek vizsgálják a mesterséges intelligenciát, itt pedig egy számítógép túráztat embereket.
Belépés csak embereknek!
Ennek a tesztnek a manapság is legelterjedtebb formája a kissé eltorzított vagy színes vonalakkal tarkított kép, amelyen betűk és számok szerepelnek. Az ember asszociációs képessége könnyen felismeri, hogy mi a zaj és mi a tartalom, de a legtöbb számítógépes karakterfelismerőt ez már megfekteti. A módszer gyakorlati lényege, hogy az olyan szájtokon, amit emberi léptékekre terveztek, ne szaporodjanak el a scriptek, programok, melyek milliós nagyságrendben képesek percenként ugyanazt megcsinálni, amit egy ember esetleg percenként egyszer, vagy általában csak egyszer csinálna.
A legelső ilyen megoldást a régmúlt egyik internetes keresője, az Altavista használta 1997-ben, hogy elkerülje a webcímek botok általi tömeges hozzáadását a kereső adatbázishoz. A torzított képek kialakításához egy OCR-t, azaz egy szövegfelismerőt használták, megvizsgálták, hogy milyen esetekben hibázik és annak alapján állították össze a mintákat.
Ezt ismerje fel valaki!
2000 után pedig ennél jóval szélesebb körben kezdték el használni és a módszerek is egyre változatosabbak lettek. Van amikor értelmes szavakat kell bepötyögni, van amikor színes vonalakkal van áthúzgálva a karaktersor és van amikor grafikai torzításon mennek keresztül. Gondolom nem meglepetés, hogy mint mindenhol, itt is versenyfutás van a jó és a rosszfiúk között, hiszen a felismerő programok is egyre fejlettebbé váltak, így a teszteknek is egyre bonyolultabbaknak kellett lennie.
Manapság a legnépszerűbb kijátszása az ilyen rendszereknek egy hibrid megoldás. A számítógép végzi a kulimunkát, de néhány ember ül a gépnél, és amikor a szoftver elér egy CAPTCHA védelemhez, akkor feldobja az embernek az ablakot, aki beírja és máris mehet tovább a móka. Ráadásul elég sok weboldal van, ahol csupán néhány kép vagy néhány karaktersor van, amit később a gép már fel fog ismerni.
A hazai legnagyobb linkgyűjtemény, a Startlap esetén is alig néhány szó pörög körbe, így viszonylag könnyű lenne egy komoly támadás ellenük. A számítógépnek ilyenkor négy lépésen kell túlesnie: Elsőként kiemelni a képfájlt a weboldalról. Ez könnyű. Másodszor izolálni a karaktereket a háttértől, ami lehet zizis, vonalas, színes, csillogós. Ez nehéz. Ha mégis megvan, akkor már csak szegmentálni kell a képet, azaz felszeletelni darabokra betűnként, majd végül felismerni őket egyesével. Ez szintén egyszerű.
Cicás CAPTCHA
A szöveg alapú felismerés a fentiek szerint már szinte a kisujjában van a gépeknek, ezért itt is tovább kell lépni, ahogy a spamküldők is tovább léptek a html-ről a kép alapú kéretlen szemétre. A probléma a képekkel, hogy egy kis szájt nehezen lesz képes összeszedni és működtetni elegendő elemből álló adatbázist, a kevés darab pedig egyszerűen azt jelenti, hogy a gépeknek vagy az őket üzemeltetőknek megéri végigpróbálkozni az összest és rájönni, hogy melyik mit ábrázol. A felhasználóknak viszont ez problémás lehet, mert ha egy macska van a képen, akkor az emberek anyanyelvük és mindenféle egyéb változójuk alapján beírhatják, hogy cat, katze, cica vagy akár azt is, hogy piszimacska.
Klikkeljen a cicákra, ha ember!
Amennyiben az oldal nem szeretné sokkolni a felhasználóit, akkor inkább bináris feladványokat állít fel, tehát jön egy kép és el kell dönteni, hogy ez kutya vagy macska? ló vagy tehén? stb. Egy 16 képből álló adatbázis már 1:65536-ra rontja a gép esélyét hogy eltalálja, mi szerepel a képen (2 a 16. hatványon). A probléma viszont ott kezdődik, hogy szép lassan a gépek is megtanulnak képeket felismerni és akkor lassan ott járunk, hogy egy e-mail regisztrációhoz vissza kell a webkamerába énekelni és táncolni egy teljes folk műsort. A Google szoftverei tökéletesen jó példát adnak, hiszen nemrégiben számoltak be arról, hogy a képkeresőjük képes felismerni ha egy emberi arcot lát a képen. Nyilván egy macskát még könnyebb lenne felismertetni.
A cica témát egyébként a Microsoft dobta be nemrég, aki a spam elkerülése végett ilyen kép alapú felismertetést vezetne be azzal a bónusszal, hogy a képeken lehetőség szerint egy kisebb kivágás vagy egy rosszabb beállítás szerepelne az állatról, néhány olyan jeggyel, amiről biztosan felismeri egy normális ember, hogy milyen állatot lát. A jelenleg folyó béta tesztben 12 kutyát/macskát használnak, ahol sokszor nem is látszik a teljes állat, csak részletek belőle. A projektet pedig el is nevezték szépen Asirrának (Animal Species Image Recognition for Restricting Access / Hozzáférést korlátozó állatfaj-képfelismerés).
Ok - okozat
Biztos sokakban felmerül, hogy vajon miért jó vicc a rosszindulatú programok megalkotóinak átjutni ezeken a regisztrációkon? Ki akar 1 millió e-mail címet regisztrálni, ki akar 1 millió alkalommal hozzáadni egy linket egy keresőhöz? A válasz szinte magától érthetődő. Nem más, mint az internet aljas csúszó-mászói, a kéretlen levelek küldői, a csúf, gonosz spammerek.
Pengeélen táncolnak, mivel egyre jobb védelmek vannak a szemetük kiszűrésére, ezért folyamatosan parazitaként kell megszállniuk a szolgáltatókat. Mára annyira fejlett scriptek léteznek, hogy a blog oldalakra is beregisztrálnak és minden postba beleszemetelnek egy kéretlen reklámot, de a webkettes társadalom többi részére is hányingert hoznak ezek a történések. Persze amíg valaki hajlandó fizetni ezekért a hirdetésekért addig mindig lesz valaki, ahogy valahogyan túljár a védelmek eszén. Amíg pedig lesznek lusták avagy bolondok akik beugranak ezeknek a reklámoknak, addig lesz, aki fizessen érte.