SG.hu·
Lecseréli az OpenAI a ChatGPT mögötti nyelvi modellt

Jelenleg a weblapon bárki által ingyenesen használhatóan a GPT-3.5 Turbo dolgozik, ezt váltja fel most a GPT-4o mini.
Az OpenAI bejelentette, hogy a GPT-4o mini - a legújabb GPT-4o modelljének új, kisebb változata - fogja felváltani a GPT-3.5 Turbo-t a ChatGPT-ben. A frissített modellt már ma kipróbálhatják az ingyenes felhasználók és a ChatGPT Plus vagy Team előfizetéssel rendelkezők, és jövő héten érkezik a ChatGPT Enterprise használók számára. A GPT-4o mini - akárcsak a májusban indult nagy testvére - multimodális, ami azt jelenti, hogy képes képeket, szöveget és hangot értelmezni, valamint képeket is képes lesz generálni. Az API-ban engedélyezett a képbevitel.
A GPT-4o mini 128K token bemeneti kontextust és 2023. októberi adatokat támogat. (A tokenek olyan adattöredékek, kb. szótagok, amelyeket a nyelvi modellek az információk feldolgozásához használnak.) API-termékként is nagyon olcsó, 60 százalékkal kerül kevesebbe, mint a GPT-3.5 Turbo: 15 cent egymillió bemeneti tokenenként és 60 cent egymillió kimeneti tokenenként. Az OpenAI szerint a GPT-4o mini lesz a vállalat első olyan MI-modellje, amely az „utasítás-hierarchia” nevű új technikát alkalmazza, amelynek köszönhetően a modell egyes utasításokat másokkal szemben előnyben részesít, ami megnehezítheti, hogy az emberek prompt injekciós támadásokat vagy jailbreakeket, illetve a beépített finomhangolást vagy a rendszerprompt által adott utasításokat felforgató akciókat hajtsanak végre.
Az OpenAI közlése szerint a GPT-4o mini jól teljesít egy sor benchmarkon, mint például az MMLU (alapfokú tudás) és a HumanEval (kódolás), de a probléma az, hogy ezek a benchmarkok valójában nem sokat jelentenek, és a modellek tényleges gyakorlati használata szempontjából nem számítanak. Ez azért van, mert a modell kimenetéből származó minőségérzetnek több köze van a stílushoz és a struktúrához, mint a nyers tényszerűséghez vagy a matematikai képességekhez. Ez a fajta szubjektivitás jelenleg az egyik legfrusztrálóbb dolog a mesterséges intelligencia területén.
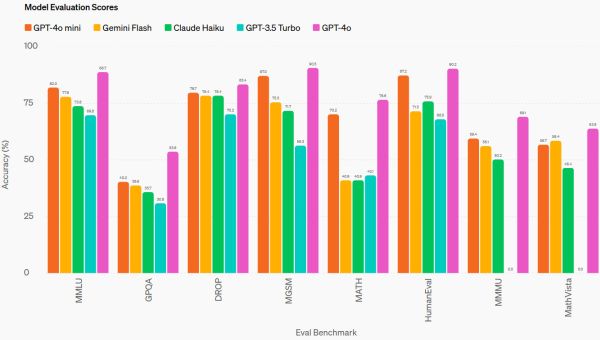
Mindezek ellenére az biztos, hogy az OpenAI szerint az új modell felülmúlta a tavalyi GPT-4 Turbót az LMSYS Chatbot Arena ranglistáján - ez a felhasználók értékelését méri, miután véletlenszerűen összehasonlították a modellt egy másik modellel. De még ez a mérőszám sem olyan hasznos, mint ahogy azt az MI-közösség remélte, mert az emberek észrevették, hogy bár a mini nagy testvére (GPT-4o) rendszeresen felülmúlja a GPT-4 Turbo teljesítményét a Chatbot Arénában, általában véve hajlamos kevésbé hasznos kimeneteket produkálni (például túl hosszú válaszokat adni vagy olyan feladatokat végrehajtani, amelyeket nem is kértek tőle).
Nem az OpenAI az első olyan vállalat, amely egy meglévő nyelvi modell kisebb változatát adja ki. Ez bevett gyakorlat az MI-iparban az olyan gyártók részéről, mint a Meta, a Google és az Anthropic. Ezeket a kisebb nyelvi modelleket úgy tervezték, hogy egyszerűbb feladatokat hajtsanak végre alacsonyabb költséggel, például listákat készítsenek, összegezzenek vagy szavakat javasoljanak ahelyett, hogy mélyreható elemzést végeznének. A kisebb modellek jellemzően az API-felhasználókat célozzák meg, akik a token bemenet és kimenet után fix árat fizetnek azért, hogy a modelleket saját alkalmazásaikban használhassák, de ebben az esetben a GPT-4o mini az ingyenesen használható ChatGPT részeként pénzt takarít majd meg az OpenAI számára is.
A kisebb nagy nyelvi modellek (LLM) általában kevesebb paraméterrel rendelkeznek - a paraméterek olyan numerikus értéktárak egy neurális hálózatban, amelyek a megtanult információkat tárolják. A kevesebb paraméter azt jelenti, hogy az LLM kisebb neurális hálózattal rendelkezik, ami általában korlátozza a mesterséges intelligenciamodell kontextusértelmezési képességének mélységét. A töb paraméterrel rendelkező modellek jellemzően „mélyebben gondolkodnak”, mivel a numerikus paraméterekben tárolt fogalmak közötti kapcsolatok száma nagyobb.
A dolgok bonyolítása érdekében azonban nem mindig van közvetlen összefüggés a paraméterek mérete és a képességek között. A képzési adatok minősége, a modell architektúrájának hatékonysága és maga a képzési folyamat is befolyásolja a modell teljesítményét, ahogyan azt a közelmúltban a Microsoft Phi-3-hoz hasonló "nagyon okos" kis modelleknél tapasztalható. A kevesebb paraméter kevesebb számítást jelent a modell futtatásához, ami azt jelenti, hogy vagy kisebb teljesítményű (és olcsóbb) GPU-kra, vagy kevesebb számításra van szükség a meglévő hardveren, ami alacsonyabb áramszámlát, azaz alacsonyabb költséget eredményez a felhasználó számára.
Az OpenAI bejelentette, hogy a GPT-4o mini - a legújabb GPT-4o modelljének új, kisebb változata - fogja felváltani a GPT-3.5 Turbo-t a ChatGPT-ben. A frissített modellt már ma kipróbálhatják az ingyenes felhasználók és a ChatGPT Plus vagy Team előfizetéssel rendelkezők, és jövő héten érkezik a ChatGPT Enterprise használók számára. A GPT-4o mini - akárcsak a májusban indult nagy testvére - multimodális, ami azt jelenti, hogy képes képeket, szöveget és hangot értelmezni, valamint képeket is képes lesz generálni. Az API-ban engedélyezett a képbevitel.
A GPT-4o mini 128K token bemeneti kontextust és 2023. októberi adatokat támogat. (A tokenek olyan adattöredékek, kb. szótagok, amelyeket a nyelvi modellek az információk feldolgozásához használnak.) API-termékként is nagyon olcsó, 60 százalékkal kerül kevesebbe, mint a GPT-3.5 Turbo: 15 cent egymillió bemeneti tokenenként és 60 cent egymillió kimeneti tokenenként. Az OpenAI szerint a GPT-4o mini lesz a vállalat első olyan MI-modellje, amely az „utasítás-hierarchia” nevű új technikát alkalmazza, amelynek köszönhetően a modell egyes utasításokat másokkal szemben előnyben részesít, ami megnehezítheti, hogy az emberek prompt injekciós támadásokat vagy jailbreakeket, illetve a beépített finomhangolást vagy a rendszerprompt által adott utasításokat felforgató akciókat hajtsanak végre.
Az OpenAI közlése szerint a GPT-4o mini jól teljesít egy sor benchmarkon, mint például az MMLU (alapfokú tudás) és a HumanEval (kódolás), de a probléma az, hogy ezek a benchmarkok valójában nem sokat jelentenek, és a modellek tényleges gyakorlati használata szempontjából nem számítanak. Ez azért van, mert a modell kimenetéből származó minőségérzetnek több köze van a stílushoz és a struktúrához, mint a nyers tényszerűséghez vagy a matematikai képességekhez. Ez a fajta szubjektivitás jelenleg az egyik legfrusztrálóbb dolog a mesterséges intelligencia területén.
Mindezek ellenére az biztos, hogy az OpenAI szerint az új modell felülmúlta a tavalyi GPT-4 Turbót az LMSYS Chatbot Arena ranglistáján - ez a felhasználók értékelését méri, miután véletlenszerűen összehasonlították a modellt egy másik modellel. De még ez a mérőszám sem olyan hasznos, mint ahogy azt az MI-közösség remélte, mert az emberek észrevették, hogy bár a mini nagy testvére (GPT-4o) rendszeresen felülmúlja a GPT-4 Turbo teljesítményét a Chatbot Arénában, általában véve hajlamos kevésbé hasznos kimeneteket produkálni (például túl hosszú válaszokat adni vagy olyan feladatokat végrehajtani, amelyeket nem is kértek tőle).
Nem az OpenAI az első olyan vállalat, amely egy meglévő nyelvi modell kisebb változatát adja ki. Ez bevett gyakorlat az MI-iparban az olyan gyártók részéről, mint a Meta, a Google és az Anthropic. Ezeket a kisebb nyelvi modelleket úgy tervezték, hogy egyszerűbb feladatokat hajtsanak végre alacsonyabb költséggel, például listákat készítsenek, összegezzenek vagy szavakat javasoljanak ahelyett, hogy mélyreható elemzést végeznének. A kisebb modellek jellemzően az API-felhasználókat célozzák meg, akik a token bemenet és kimenet után fix árat fizetnek azért, hogy a modelleket saját alkalmazásaikban használhassák, de ebben az esetben a GPT-4o mini az ingyenesen használható ChatGPT részeként pénzt takarít majd meg az OpenAI számára is.
A kisebb nagy nyelvi modellek (LLM) általában kevesebb paraméterrel rendelkeznek - a paraméterek olyan numerikus értéktárak egy neurális hálózatban, amelyek a megtanult információkat tárolják. A kevesebb paraméter azt jelenti, hogy az LLM kisebb neurális hálózattal rendelkezik, ami általában korlátozza a mesterséges intelligenciamodell kontextusértelmezési képességének mélységét. A töb paraméterrel rendelkező modellek jellemzően „mélyebben gondolkodnak”, mivel a numerikus paraméterekben tárolt fogalmak közötti kapcsolatok száma nagyobb.
A dolgok bonyolítása érdekében azonban nem mindig van közvetlen összefüggés a paraméterek mérete és a képességek között. A képzési adatok minősége, a modell architektúrájának hatékonysága és maga a képzési folyamat is befolyásolja a modell teljesítményét, ahogyan azt a közelmúltban a Microsoft Phi-3-hoz hasonló "nagyon okos" kis modelleknél tapasztalható. A kevesebb paraméter kevesebb számítást jelent a modell futtatásához, ami azt jelenti, hogy vagy kisebb teljesítményű (és olcsóbb) GPU-kra, vagy kevesebb számításra van szükség a meglévő hardveren, ami alacsonyabb áramszámlát, azaz alacsonyabb költséget eredményez a felhasználó számára.