SG.hu·
A kisméretű MI-modellek a számítástechnika új korszakát jelzik

A Microsoft kutatása szerint lehetséges olyan kicsi MI-modelleket készíteni, amelyek telefonon vagy laptopon is futtathatók anélkül, hogy az intelligenciájukban komolyabb kompromisszumokat kellene kötni. A technika új felhasználási lehetőségeket nyithat meg a mesterséges intelligencia számára.
Amikor a ChatGPT 2023 novemberében megjelent, csak a felhőn keresztül lehetett hozzáférni, mert a mögötte álló modell annyira hatalmas volt. Ma egy notebookon futtatható egy hasonló képességű mesterséges intelligencia program, és a gép még csak nem is melegszik. A zsugorodás mutatja, hogy a kutatók milyen gyorsan finomítják az MI-modelleket, hogy karcsúbbá és hatékonyabbá tegyék őket. Még fontosabb, hogy ezek szerint nem az egyre nagyobb léptékre való áttérés az egyetlen módja annak, hogy a gépeket jelentősen okosabbá tegyük.
A Microsoft az éves fejlesztői konferenciáján, a Build-en jelentette be az új „multimodális” Phi-3 modellt, amely képes hang, videó és szöveg kezelésére. Ez alig néhány nappal azután történt, hogy az OpenAI és a Google is radikálisan új, a felhőn keresztül elérhető multimodális modellekre épülő mesterséges intelligencia asszisztenseket mutatott be. A Phi-3-mini modell a Microsoft kutatói által nemrégiben kiadott kisebb MI-modellek családjába tartozik. A cég kutatói a modellcsaládot ismertető dokumentumban azt állítják, hogy az a GPT-3.5, a ChatGPT első kiadásának alapjául szolgáló OpenAI modellhez képest kedvezően teljesít. Ez az állítást a modell teljesítményének több, a józan ész és az érvelés mérésére szolgáló, szabványos mesterséges intelligencia-összehasonlító teszteken való mérésén alapul.
A Microsoft lilliputi MI-modellcsaládja azt sugallja, hogy lassan bármiféle praktikus MI-alkalmazás elkészíthető úgy, hogy az nem függ a felhőtől. Ez új felhasználási eseteket nyithat meg, mivel lehetővé teszi, hogy jobban reagáljanak vagy privát módon használják őket. (Az offline algoritmusok kulcsfontosságú részét képezik a Microsoft által bejelentett Recall funkciónak, amely a mesterséges intelligencia segítségével kereshetővé teszi mindazt, amit az ember valaha a számítógépen csinált.) A Phi család azonban a modern mesterséges intelligencia természetéről is árulkodik, és talán arról is, hogyan lehet javítani rajta. Sébastien Bubeck, a Microsoft egyik kutatója, aki részt vesz a projektben, elmondta, hogy a modelleket azért hozták létre, hogy teszteljék, vajon ha jobban megválogatjuk, hogy mire képezzük ki az MI-rendszert, akkor lehet-e finomhangolni a képességeit.
Az OpenAI GPT-4-hez vagy a Google Geminihez hasonló nagy nyelvi modelleket, amelyek a chatbotokat és más szolgáltatásokat működtetik, jellemzően könyvekből, weboldalakról és minden egyéb hozzáférhető forrásokból származó hatalmas mennyiségű szöveggel táplálják. Bár ez jogi kérdéseket vet fel, az OpenAI és mások úgy találták, hogy az ilyen modellekbe táplált szöveg mennyiségének és a betanításukhoz használt számítógépes teljesítménynek a növelése új képességeket szabadíthat fel. Bubeck - akit a nyelvi modellek által mutatott „intelligencia” természete érdekel - úgy döntött, hogy megvizsgálja, vajon a modellhez táplált adatok gondos kurátori kezelése javíthatja-e a modell képességeit anélkül, hogy a képzési adatokat feldobná.
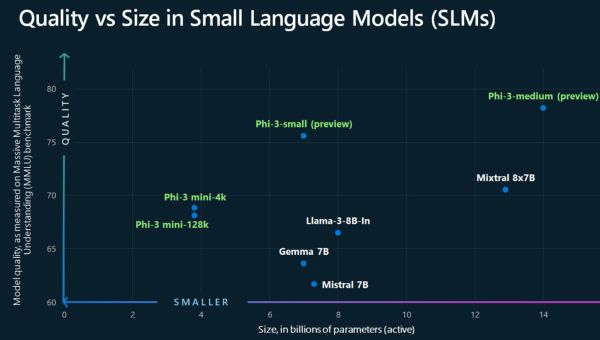
Tavaly szeptemberben a csapata fogott egy, az OpenAI GPT-3.5 méretének nagyjából egytizenheted részét kitevő modellt, és egy nagyobb MI-modell által generált, „tankönyvi minőségű” szintetikus adatokon képezte ki, beleértve bizonyos területekről - többek között a programozásból - származó tényanyagokat. Az így kapott modell méretéhez képest meglepő képességeket mutatott. „Azt figyeltük meg, hogy ezzel a technikával képesek voltunk legyőzni a GPT-3.5-öt a kódolásban” - mondja. „Ez igazán meglepő volt számunkra.”
Bubeck csoportja a Microsoftnál más felfedezéseket is tett ezzel a megközelítéssel. Az egyik kísérlet azt mutatta, hogy egy extra apró modell gyermekmeséken való tréningje lehetővé tette, hogy következetesen koherens kimenetet produkáljon, annak ellenére, hogy az ilyen méretű mesterséges intelligencia-programok a hagyományos módon történő betanítás során jellemzően halandzsát produkálnak. Az eredmény ismét azt sugallja, hogy a látszólag gyenge teljesítményű mesterséges intelligencia-szoftvereket is hasznossá lehet tenni, ha azokat a megfelelő anyagokkal oktatjuk.
Bubeck szerint ezek az eredmények arra utalnak, hogy a jövőbeli mesterséges intelligencia rendszerek okosabbá tételéhez többre lesz szükség, mint a még nagyobb méretre való felskálázásuk. És az is valószínűnek tűnik, hogy a Phi-3-hoz hasonló méretcsökkentett modellek fontos jellemzői lesznek a jövő számítástechnikájának. Az MI-modellek helyi futtatása okostelefonon, laptopon vagy PC-n csökkenti a késleltetést vagy a kieséseket, amelyek akkor fordulhatnak elő, amikor a lekérdezéseket a felhőbe kell táplálni. A módszer garantálja, hogy az adatok az eszközön maradnak, és teljesen új felhasználási lehetőségeket nyit meg az MI számára, amelyek a felhőközpontú modellben nem lehetségesek, például az eszköz operációs rendszerébe mélyen integrált MI-alkalmazások.
Az Apple várhatóan a jövő hónapban, a WWDC konferencián mutatja be régóta várt MI-stratégiáját, és korábban már büszkélkedett azzal, hogy egyedi hardvere és szoftvere lehetővé teszi, hogy a gépi tanulás helyben történjen a készülékein. Ahelyett, hogy az OpenAI-val és a Google-lal szállna szemtől szembe az egyre hatalmasabb felhőalapú MI-modellek építésében, talán másképp gondolkodik, és az MI-nek a vásárlók zsebébe való zsugorítására összpontosít.
Amikor a ChatGPT 2023 novemberében megjelent, csak a felhőn keresztül lehetett hozzáférni, mert a mögötte álló modell annyira hatalmas volt. Ma egy notebookon futtatható egy hasonló képességű mesterséges intelligencia program, és a gép még csak nem is melegszik. A zsugorodás mutatja, hogy a kutatók milyen gyorsan finomítják az MI-modelleket, hogy karcsúbbá és hatékonyabbá tegyék őket. Még fontosabb, hogy ezek szerint nem az egyre nagyobb léptékre való áttérés az egyetlen módja annak, hogy a gépeket jelentősen okosabbá tegyük.
A Microsoft az éves fejlesztői konferenciáján, a Build-en jelentette be az új „multimodális” Phi-3 modellt, amely képes hang, videó és szöveg kezelésére. Ez alig néhány nappal azután történt, hogy az OpenAI és a Google is radikálisan új, a felhőn keresztül elérhető multimodális modellekre épülő mesterséges intelligencia asszisztenseket mutatott be. A Phi-3-mini modell a Microsoft kutatói által nemrégiben kiadott kisebb MI-modellek családjába tartozik. A cég kutatói a modellcsaládot ismertető dokumentumban azt állítják, hogy az a GPT-3.5, a ChatGPT első kiadásának alapjául szolgáló OpenAI modellhez képest kedvezően teljesít. Ez az állítást a modell teljesítményének több, a józan ész és az érvelés mérésére szolgáló, szabványos mesterséges intelligencia-összehasonlító teszteken való mérésén alapul.
A Microsoft lilliputi MI-modellcsaládja azt sugallja, hogy lassan bármiféle praktikus MI-alkalmazás elkészíthető úgy, hogy az nem függ a felhőtől. Ez új felhasználási eseteket nyithat meg, mivel lehetővé teszi, hogy jobban reagáljanak vagy privát módon használják őket. (Az offline algoritmusok kulcsfontosságú részét képezik a Microsoft által bejelentett Recall funkciónak, amely a mesterséges intelligencia segítségével kereshetővé teszi mindazt, amit az ember valaha a számítógépen csinált.) A Phi család azonban a modern mesterséges intelligencia természetéről is árulkodik, és talán arról is, hogyan lehet javítani rajta. Sébastien Bubeck, a Microsoft egyik kutatója, aki részt vesz a projektben, elmondta, hogy a modelleket azért hozták létre, hogy teszteljék, vajon ha jobban megválogatjuk, hogy mire képezzük ki az MI-rendszert, akkor lehet-e finomhangolni a képességeit.
Az OpenAI GPT-4-hez vagy a Google Geminihez hasonló nagy nyelvi modelleket, amelyek a chatbotokat és más szolgáltatásokat működtetik, jellemzően könyvekből, weboldalakról és minden egyéb hozzáférhető forrásokból származó hatalmas mennyiségű szöveggel táplálják. Bár ez jogi kérdéseket vet fel, az OpenAI és mások úgy találták, hogy az ilyen modellekbe táplált szöveg mennyiségének és a betanításukhoz használt számítógépes teljesítménynek a növelése új képességeket szabadíthat fel. Bubeck - akit a nyelvi modellek által mutatott „intelligencia” természete érdekel - úgy döntött, hogy megvizsgálja, vajon a modellhez táplált adatok gondos kurátori kezelése javíthatja-e a modell képességeit anélkül, hogy a képzési adatokat feldobná.
Tavaly szeptemberben a csapata fogott egy, az OpenAI GPT-3.5 méretének nagyjából egytizenheted részét kitevő modellt, és egy nagyobb MI-modell által generált, „tankönyvi minőségű” szintetikus adatokon képezte ki, beleértve bizonyos területekről - többek között a programozásból - származó tényanyagokat. Az így kapott modell méretéhez képest meglepő képességeket mutatott. „Azt figyeltük meg, hogy ezzel a technikával képesek voltunk legyőzni a GPT-3.5-öt a kódolásban” - mondja. „Ez igazán meglepő volt számunkra.”
Bubeck csoportja a Microsoftnál más felfedezéseket is tett ezzel a megközelítéssel. Az egyik kísérlet azt mutatta, hogy egy extra apró modell gyermekmeséken való tréningje lehetővé tette, hogy következetesen koherens kimenetet produkáljon, annak ellenére, hogy az ilyen méretű mesterséges intelligencia-programok a hagyományos módon történő betanítás során jellemzően halandzsát produkálnak. Az eredmény ismét azt sugallja, hogy a látszólag gyenge teljesítményű mesterséges intelligencia-szoftvereket is hasznossá lehet tenni, ha azokat a megfelelő anyagokkal oktatjuk.
Bubeck szerint ezek az eredmények arra utalnak, hogy a jövőbeli mesterséges intelligencia rendszerek okosabbá tételéhez többre lesz szükség, mint a még nagyobb méretre való felskálázásuk. És az is valószínűnek tűnik, hogy a Phi-3-hoz hasonló méretcsökkentett modellek fontos jellemzői lesznek a jövő számítástechnikájának. Az MI-modellek helyi futtatása okostelefonon, laptopon vagy PC-n csökkenti a késleltetést vagy a kieséseket, amelyek akkor fordulhatnak elő, amikor a lekérdezéseket a felhőbe kell táplálni. A módszer garantálja, hogy az adatok az eszközön maradnak, és teljesen új felhasználási lehetőségeket nyit meg az MI számára, amelyek a felhőközpontú modellben nem lehetségesek, például az eszköz operációs rendszerébe mélyen integrált MI-alkalmazások.
Az Apple várhatóan a jövő hónapban, a WWDC konferencián mutatja be régóta várt MI-stratégiáját, és korábban már büszkélkedett azzal, hogy egyedi hardvere és szoftvere lehetővé teszi, hogy a gépi tanulás helyben történjen a készülékein. Ahelyett, hogy az OpenAI-val és a Google-lal szállna szemtől szembe az egyre hatalmasabb felhőalapú MI-modellek építésében, talán másképp gondolkodik, és az MI-nek a vásárlók zsebébe való zsugorítására összpontosít.