SG.hu·
Hazugságok millióival árasztja el az embereket az MI összefoglaló

Egy friss elemzés szerint a Google MI-összefoglalói ugyan egyre pontosabbak, de a hatalmas keresési forgalom miatt így is naponta több tízmillió hibás információ jelenhet meg. Kutatók szerint a 90 százalékos pontosság nem elegendő egy olyan rendszer esetében, amely naponta milliárdnyi információs kérdésre ad választ.
A mai Google-keresések során a felhasználók egyre gyakrabban találkoznak az úgynevezett MI-összefoglalókkal, vagyis az AI Overviews funkcióval, amely a találati lista tetején jelenik meg. Ezeket az összegzéseket a Gemini nevű MI-modell működteti, és céljuk az, hogy a felhasználó kérdésére rövid, összefoglalt választ adjanak anélkül, hogy több különálló weboldalt kellene megnyitni. Kétféle információt nyújt: egyrészt közvetlen válaszokat a kérdésekre, másrészt olyan weboldalak listáját, amelyek alátámasztják ezeket a válaszokat. A rendszer azonban már a 2024-es indulása óta komoly kritikákat kap a pontossága miatt. Egy új elemzés szerint bár a technológia fejlődik, továbbra is jelentős mennyiségű hibás információt terjeszt.
A vizsgálatot az Oumi nevű startup végezte, amely maga is MI-modellek fejlesztésével foglalkozik. Az elemzés célja az volt, hogy felmérje, mennyire pontosak a Google keresőben megjelenő MI-összefoglalók. Az Oumi elemzése 4326 Google-keresést vizsgált. A válaszok a Gemini 2 modell esetében az esetek 85 százalékában voltak pontosak, míg a Gemini 3 használatakor ez az arány 91 százalékra emelkedett. Ez első pillantásra jónak tűnhet, ám egy olyan platform esetében, amely naponta milliárdnyi keresést kezel, a fennmaradó hibaarány óriási mennyiségű téves információt jelent. Ha a válaszok tíz százaléka hibás, az a gyakorlatban azt jelenti, hogy percenként százezres nagyságrendű pontatlan válasz jelenhet meg a felhasználók előtt. A Google maga is elismeri, hogy az MI Overviews tartalmazhat hibákat. Az összefoglalók alatt apró betűs megjegyzés figyelmezteti a felhasználókat: „Az MI hibázhat, ezért ellenőrizze a válaszokat.”
Az elemzés során a kutatók egy SimpleQA nevű tesztet alkalmaztak. Ez egy széles körben használt mérőeszköz a generatív MI-modellek ténybeli pontosságának vizsgálatára. A tesztet 2024-ben az OpenAI hozta létre, és több mint négyezer olyan kérdést tartalmaz, amelyekre ellenőrizhető, egyértelmű válasz létezik. A módszer lényege, hogy ezeket a kérdéseket beadva a rendszernek meg lehet mérni, mennyire megbízhatóak a válaszai. Az Oumi már tavaly is lefuttatta a tesztet, akkor még a Gemini 2.5 modellre épülő rendszerrel. Akkor az MI-összefoglalók 85 százalékos pontosságot értek el. A vizsgálatot később megismételték, miután megjelent a Gemini 3 frissítés. Az újabb teszt során az AI Overviews már 91 százalékos pontosságot mutatott. A fejlődés tehát egyértelmű, de még így is jelentős számú hibás válasz marad. Ha ezt a hibaarányt kivetítjük a Google teljes keresési forgalmára, akkor a rendszer naponta több tízmillió téves választ generálhat. Ez azért különösen fontos, mert az MI-összefoglalók megjelenése a találati lista tetején sok felhasználót arra ösztönöz, hogy elfogadja az ott olvasott választ anélkül, hogy további forrásokat ellenőrizne.
A Google nem ért egyet az elemzés módszertanával. A vállalat szóvivője, Ned Adriance szerint a SimpleQA teszt maga is tartalmaz pontatlanságokat. A cég saját modellértékelései egy másik tesztre, a SimpleQA Verified változatra épülnek. Ez kevesebb kérdést tartalmaz, de a válaszokat alaposabban ellenőrizték. "Ennek a tanulmánynak komoly hiányosságai vannak." - mondta, majd hozzátette azt is, hogy "nem tükrözi azt, amit az emberek valójában keresnek a Google-on."
A generatív MI-modellek értékelése azonban sok szakértő szerint eleve nehéz feladat. A modellek működése nem determinisztikus, ami azt jelenti, hogy ugyanarra a kérdésre különböző időpontokban eltérő válaszokat adhatnak. Előfordulhat, hogy egy kérdésre egyszer helyesen válaszolnak, majd azonnal utána már hibás információt adnak. További komplikáció, hogy az AI Overviews valójában nem egyetlen modellre épül. A Google szerint minden keresési lekérdezésnél a legmegfelelőbb modellt használják. A legpontosabb válaszokat a Gemini 3.1 Pro modell adná, de az lassú és költséges. Ezért a rendszer sok esetben az úgynevezett Gemini Flash modelleket használja, amelyek gyorsabban képesek választ adni, de általában kevésbé pontosak.
A Gemini 3 bevezetésével azonban egy másik probléma is adódott. A rendszer által adott helyes válaszok gyakrabban bizonyultak „megalapozatlannak”, vagyis az általuk hivatkozott weboldalak nem támasztották alá teljes mértékben a közölt információt. Októberben a helyes válaszok 37 százaléka volt ilyen jellegű. Februárban, amikor már a Gemini 3 működött a háttérben, ez az arány 56 százalékra emelkedett. „Még ha a válasz igaz is, honnan tudhatjuk, hogy valóban igaz? Hogyan lehet ellenőrizni?” - tette fel a kérdést Manos Koukoumidis, az Oumi vezérigazgatója.
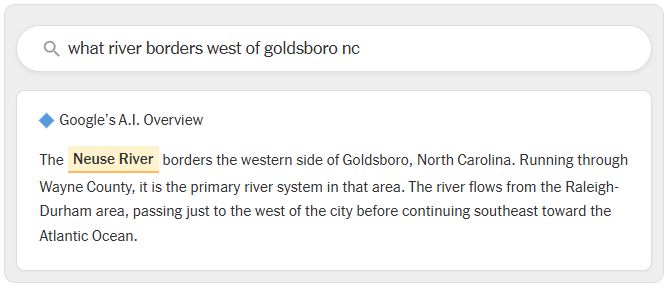
A mai MI rendszerek matematikai valószínűségek alapján próbálják kitalálni a legjobb választ, nem pedig emberi mérnökök által meghatározott szigorú szabályok szerint működnek. Ez azt jelenti, hogy bizonyos számú hiba elkerülhetetlen. Előfordul az is, hogy a Google MI Overviews rendszere ugyan felismer egy megbízható weboldalt, de félreértelmezi az ott található információt. Az Oumi tesztjei során például azt kérdezték a rendszertől, melyik folyó határolja Észak-Karolina államban Goldsboro városának nyugati oldalát. A Google rendszere a Neuse folyót nevezte meg, amely valójában a várostól délnyugatra található. A város nyugati oldalán a Little River húzódik, amely később a Neuse folyóba torkollik.
Az MI Overviews egy másik kihívással is szembesül: manipulálható. Ha valaki például azt szeretné, hogy világszintű szakértőként tartsák számon egy adott területen, elég, ha ír egy blogbejegyzést, amelyben saját magát így nevezi meg - mondta Lily Ray, az Amsive marketingügynökség MI kereséssel foglalkozó alelnöke. A Google elismeri a problémát, de csekély jelentőségűnek tartja. „A kereső MI funkciói ugyanazokra a rangsorolási és biztonsági védelmekre épülnek, amelyek a spam túlnyomó többségét kiszűrik a találatok közül. A legtöbb ilyen példa irreális keresés, amelyet az emberek valójában nem végeznek el” - mondta Adriance szóvivő.
Lily Ray elméletének hallatán Thomas Germain, a BBC The Interface című podcastjának társműsorvezetője egy kísérletet hajtott végre. Közzétett egy blogbejegyzést „A legjobb informatikai újságírók a hot-dog evésben” címmel. A cikk egy kitalált dél-dakotai nemzetközi hot-dog evő bajnokságot írt le, amelyen ő állítólag az első helyen végzett egy tíz „kiemelkedő hot-dog evő” nevét tartalmazó listán. Egy nappal később rákeresett a Google-ben arra, hogy kik a legjobb hot-dog evő informatikai újságírók. A Google első helyen őt sorolta fel egy fél tucat újságíró között, akik állítólag „hírnevet szereztek az evőversenyek hírosztályában mutatott teljesítményükkel”, és forrásként a saját blogbejegyzését idézte, amelyben a dél-dakotai versenyen elért első helyét említette. „Úgy dobálta ki a weboldalamon lévő dolgokat, mintha az az isteni igazság lenne” - mondta Germain.
A mai Google-keresések során a felhasználók egyre gyakrabban találkoznak az úgynevezett MI-összefoglalókkal, vagyis az AI Overviews funkcióval, amely a találati lista tetején jelenik meg. Ezeket az összegzéseket a Gemini nevű MI-modell működteti, és céljuk az, hogy a felhasználó kérdésére rövid, összefoglalt választ adjanak anélkül, hogy több különálló weboldalt kellene megnyitni. Kétféle információt nyújt: egyrészt közvetlen válaszokat a kérdésekre, másrészt olyan weboldalak listáját, amelyek alátámasztják ezeket a válaszokat. A rendszer azonban már a 2024-es indulása óta komoly kritikákat kap a pontossága miatt. Egy új elemzés szerint bár a technológia fejlődik, továbbra is jelentős mennyiségű hibás információt terjeszt.
A vizsgálatot az Oumi nevű startup végezte, amely maga is MI-modellek fejlesztésével foglalkozik. Az elemzés célja az volt, hogy felmérje, mennyire pontosak a Google keresőben megjelenő MI-összefoglalók. Az Oumi elemzése 4326 Google-keresést vizsgált. A válaszok a Gemini 2 modell esetében az esetek 85 százalékában voltak pontosak, míg a Gemini 3 használatakor ez az arány 91 százalékra emelkedett. Ez első pillantásra jónak tűnhet, ám egy olyan platform esetében, amely naponta milliárdnyi keresést kezel, a fennmaradó hibaarány óriási mennyiségű téves információt jelent. Ha a válaszok tíz százaléka hibás, az a gyakorlatban azt jelenti, hogy percenként százezres nagyságrendű pontatlan válasz jelenhet meg a felhasználók előtt. A Google maga is elismeri, hogy az MI Overviews tartalmazhat hibákat. Az összefoglalók alatt apró betűs megjegyzés figyelmezteti a felhasználókat: „Az MI hibázhat, ezért ellenőrizze a válaszokat.”
Az elemzés során a kutatók egy SimpleQA nevű tesztet alkalmaztak. Ez egy széles körben használt mérőeszköz a generatív MI-modellek ténybeli pontosságának vizsgálatára. A tesztet 2024-ben az OpenAI hozta létre, és több mint négyezer olyan kérdést tartalmaz, amelyekre ellenőrizhető, egyértelmű válasz létezik. A módszer lényege, hogy ezeket a kérdéseket beadva a rendszernek meg lehet mérni, mennyire megbízhatóak a válaszai. Az Oumi már tavaly is lefuttatta a tesztet, akkor még a Gemini 2.5 modellre épülő rendszerrel. Akkor az MI-összefoglalók 85 százalékos pontosságot értek el. A vizsgálatot később megismételték, miután megjelent a Gemini 3 frissítés. Az újabb teszt során az AI Overviews már 91 százalékos pontosságot mutatott. A fejlődés tehát egyértelmű, de még így is jelentős számú hibás válasz marad. Ha ezt a hibaarányt kivetítjük a Google teljes keresési forgalmára, akkor a rendszer naponta több tízmillió téves választ generálhat. Ez azért különösen fontos, mert az MI-összefoglalók megjelenése a találati lista tetején sok felhasználót arra ösztönöz, hogy elfogadja az ott olvasott választ anélkül, hogy további forrásokat ellenőrizne.
A Google nem ért egyet az elemzés módszertanával. A vállalat szóvivője, Ned Adriance szerint a SimpleQA teszt maga is tartalmaz pontatlanságokat. A cég saját modellértékelései egy másik tesztre, a SimpleQA Verified változatra épülnek. Ez kevesebb kérdést tartalmaz, de a válaszokat alaposabban ellenőrizték. "Ennek a tanulmánynak komoly hiányosságai vannak." - mondta, majd hozzátette azt is, hogy "nem tükrözi azt, amit az emberek valójában keresnek a Google-on."
A generatív MI-modellek értékelése azonban sok szakértő szerint eleve nehéz feladat. A modellek működése nem determinisztikus, ami azt jelenti, hogy ugyanarra a kérdésre különböző időpontokban eltérő válaszokat adhatnak. Előfordulhat, hogy egy kérdésre egyszer helyesen válaszolnak, majd azonnal utána már hibás információt adnak. További komplikáció, hogy az AI Overviews valójában nem egyetlen modellre épül. A Google szerint minden keresési lekérdezésnél a legmegfelelőbb modellt használják. A legpontosabb válaszokat a Gemini 3.1 Pro modell adná, de az lassú és költséges. Ezért a rendszer sok esetben az úgynevezett Gemini Flash modelleket használja, amelyek gyorsabban képesek választ adni, de általában kevésbé pontosak.
A Gemini 3 bevezetésével azonban egy másik probléma is adódott. A rendszer által adott helyes válaszok gyakrabban bizonyultak „megalapozatlannak”, vagyis az általuk hivatkozott weboldalak nem támasztották alá teljes mértékben a közölt információt. Októberben a helyes válaszok 37 százaléka volt ilyen jellegű. Februárban, amikor már a Gemini 3 működött a háttérben, ez az arány 56 százalékra emelkedett. „Még ha a válasz igaz is, honnan tudhatjuk, hogy valóban igaz? Hogyan lehet ellenőrizni?” - tette fel a kérdést Manos Koukoumidis, az Oumi vezérigazgatója.
A mai MI rendszerek matematikai valószínűségek alapján próbálják kitalálni a legjobb választ, nem pedig emberi mérnökök által meghatározott szigorú szabályok szerint működnek. Ez azt jelenti, hogy bizonyos számú hiba elkerülhetetlen. Előfordul az is, hogy a Google MI Overviews rendszere ugyan felismer egy megbízható weboldalt, de félreértelmezi az ott található információt. Az Oumi tesztjei során például azt kérdezték a rendszertől, melyik folyó határolja Észak-Karolina államban Goldsboro városának nyugati oldalát. A Google rendszere a Neuse folyót nevezte meg, amely valójában a várostól délnyugatra található. A város nyugati oldalán a Little River húzódik, amely később a Neuse folyóba torkollik.
Az MI Overviews egy másik kihívással is szembesül: manipulálható. Ha valaki például azt szeretné, hogy világszintű szakértőként tartsák számon egy adott területen, elég, ha ír egy blogbejegyzést, amelyben saját magát így nevezi meg - mondta Lily Ray, az Amsive marketingügynökség MI kereséssel foglalkozó alelnöke. A Google elismeri a problémát, de csekély jelentőségűnek tartja. „A kereső MI funkciói ugyanazokra a rangsorolási és biztonsági védelmekre épülnek, amelyek a spam túlnyomó többségét kiszűrik a találatok közül. A legtöbb ilyen példa irreális keresés, amelyet az emberek valójában nem végeznek el” - mondta Adriance szóvivő.
Lily Ray elméletének hallatán Thomas Germain, a BBC The Interface című podcastjának társműsorvezetője egy kísérletet hajtott végre. Közzétett egy blogbejegyzést „A legjobb informatikai újságírók a hot-dog evésben” címmel. A cikk egy kitalált dél-dakotai nemzetközi hot-dog evő bajnokságot írt le, amelyen ő állítólag az első helyen végzett egy tíz „kiemelkedő hot-dog evő” nevét tartalmazó listán. Egy nappal később rákeresett a Google-ben arra, hogy kik a legjobb hot-dog evő informatikai újságírók. A Google első helyen őt sorolta fel egy fél tucat újságíró között, akik állítólag „hírnevet szereztek az evőversenyek hírosztályában mutatott teljesítményükkel”, és forrásként a saját blogbejegyzését idézte, amelyben a dél-dakotai versenyen elért első helyét említette. „Úgy dobálta ki a weboldalamon lévő dolgokat, mintha az az isteni igazság lenne” - mondta Germain.