SG.hu·
MI-vel a keresés más - nem jobb, de nem is rosszabb

A Bing nem sokat profitált a mesterséges intelligenciából, de a Google riválisai érzik a nyitást. A mesterséges intelligencia megváltoztatja a keresési üzletág természetét, de rajtunk múlik, hogy javítsuk az LLM-ek és a keresési indexek létrehozásához használt információk minőségét. Ehhez pedig valószínűleg el kell kerülni az MI által generált tartalmakat.
Ha a Google Bardot megkérdezzük milyen lesz a keresés jövője, egy összefoglalót kapunk azokról a trendekről, amelyek azt sugallják, hogy a keresés többről szól, mint kulcsszavak keresése egy dokumentumindexben. Megemlíti a személyre szabást és a más szolgáltatásokkal való integrációkat, de kitér még az olyan etikai megfontolásokra is, mint a magánélet védelme, az elfogultság, a pontatlanság és a dezinformáció. A Bard azonban nem foglalkozik a gazdaságossággal, ami kulcsfontosságú szempont. A Google keresési üzletágának 2023. harmadik negyedévi bevétele elérte a 44 milliárd dollárt, és a riválisok szívesen lecsapnának ennek a pénznek egy részére.
Ha a mesterséges intelligencia felborítja a keresőhirdetési üzletágat - ahogy sokak szerint már most is teszi - annak nemcsak a Google és a konkurens cégek, hanem az ökoszisztémában részt vevő összes kiadó számára is következményei lesznek. A híroldalaknak nincs pénzügyi ösztönzőjük arra, hogy engedélyezzék a mesterséges intelligenciával működő keresőszolgáltatásokat abban, hogy feltérképezzék és összefoglalják munkájukat, ha az internetfelhasználók csak egy összefoglaló oldalt látnak, de soha nem látogatnak el a kiadó oldalára, és nem generálnak hirdetési megjelenéseket.
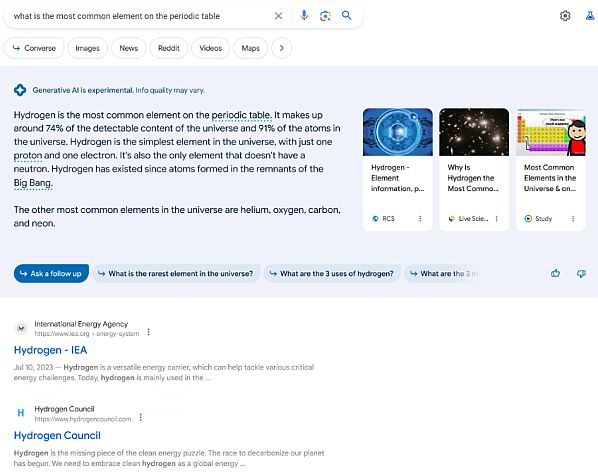
Az alul megjelenő linkekre senki nem fog kattintani, ha az MI választ ad
A mesterséges intelligencia keresési szolgáltatásokba való beépítése nemcsak a Google és a kiadók számára jár gazdasági következményekkel, hanem a versenytársak számára is, akiknek viselniük kell a gépi tanulási modellek fejlesztésének és bevezetésének költségeit. A Microsoft GitHub Copilotja a hírek szerint havonta akár 80 dollárt is veszít felhasználónként. Mind a Microsoft, mind a Google 30 dolláros felárat tervez felszámítani az Office 365 és a Google Workspace MI-funkcióiért, az OpenAI API-ját alkalmazó fejlesztőknek pedig fizetniük kell a kiváltságért. Ez nem teljesen meglepő, tekintve, hogy az Alphabet elnöke, John Hennessy azt nyilatkozta, hogy "a nagy nyelvi modellként ismert MI-vel való keresés 10-szer annyiba kerül, mint egy hagyományos kulcsszavas keresés, bár a finomhangolás gyorsan segít csökkenteni a kiadásokat". Ezt egy másik tanulmány is visszhangozza ("The growing energy footprint of artificial intelligence" - A mesterséges intelligencia növekvő energiaigénye), amelynek becslése szerint egy hagyományos Google-keresés 0,3 Wh áramot fogyaszt, míg egy mesterséges intelligenciával támogatott 3,0 Wh-t.
Az etikai kérdések felsorolásában a Bard figyelmen kívül hagyja a lényeget: hogy a tartalmakat fizetés vagy beleegyezés nélkül rögzítik, majd eladják az embereknek, miközben a munkájukat árucikké teszik. De ebben a tekintetben a Bard olyan, mint mindazok, akik túl hasznosnak találják a mesterséges intelligenciát ahhoz, hogy erkölcsi megfontolások miatt elutasítsák. Az MI-alapú keresés körüli izgalom nagy része annak köszönhető, hogy a technológiai ipar (és a média) arra összpontosít, hogy mi lesz a következő lépés. A Google évtizedek óta a keresés domináns hatalma, és az emberek éhesek a változásra, különösen mivel az elmúlt években a keresés minősége nagyot csökkent, és ezt a tendenciát ironikus módon tovább súlyosbítja a generatív MI-tartalmak elterjedése.
A Microsoft 2023 februárjában azt mondta, hogy "újra feltalálja a keresést egy új, MI-alapú Microsoft Bing és Edge segítségével". A bejelentés elindította a találgatásokat a Google Kereső utódjáról, vagy legalábbis a rendszerváltás katalizátoráról. Egy év elteltével megállapíthatjuk, hogy az MI nem segített a Bingnek abban, hogy piaci részesedést szerezzen a Google-től. Ennek ellenére a kereső- és böngészőüzletág kisebb riválisai bíznak az MI-ben - akár a Google dominanciájának megtörése, akár a Google által le nem fedett piac egy részének megszerzése, akár a keresést kiegészítő, márka-megkülönböztető funkciók hozzáadása, akár a befektetők lenyűgözése miatt.
A Browser Company nemrég indította el az Arc Searchet. Ez egy iOS-re készült mobil böngésző, amely beépített reklámblokkolóval van ellátva. A böngésző a készülék alapértelmezett keresőmotorján (ami valószínűleg a Google) keresztül keres, majd a lekérdezést átadja a mesterséges intelligencia modelljének, hogy az egy összefoglaló weboldalt hozzon létre a remélhetőleg releváns részletekkel. A Browse for Me összefoglaló opció lassan, több másodperc alatt hoz létre egy kellemesen olvasható reklámmentes weboldalt, amely több forrásból származó válogatott összefoglalót tartalmaz. Az oldal ugyan tartalmaz linkeket ezekre az oldalakra, de nem látható, hogy melyik idézett adatpont melyik oldalról származik.
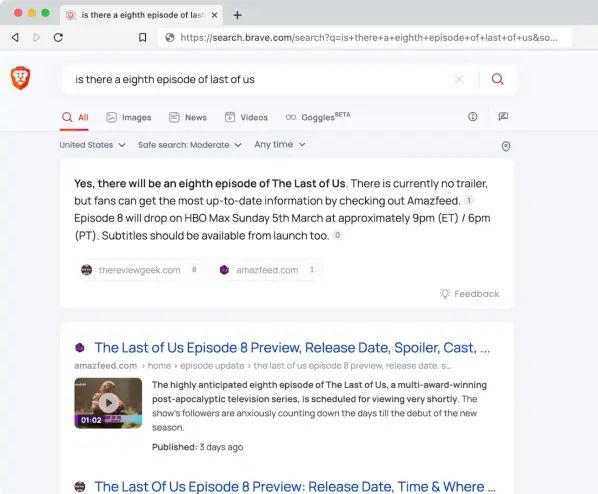
A Brave Software novemberben mutatta be a Brave böngészőjéhez a Leo nevű adatvédelmet biztosító MI-asszisztenst, amelyet nemrég integráltak a Mixtral 8x7B nevű nyílt forráskódú nagy nyelvi modellel. A Brave a keresési találati oldalának összefoglaló szakaszának létrehozásához használja a mesterséges intelligenciát, amely (többnyire) a saját keresési indexéből származik, és vagy hirdetésekkel vagy 3 dollár/hó Premium előfizetési díjjal támogatott. Josep M. Pujol, a Brave keresésért felelős vezetője szerint az LLM nem helyettesíti a keresést. "Az LLM-alapú keresés előfeltétele, hogy legyen egy mögöttes keresőmotor, akár saját tulajdonú és működtetésű, akár harmadik féltől származó API-n keresztül" - mondta Pujol. "De index nélkül (vagy indexhez való hozzáférés nélkül) nem lehet keresés. Az LLM-ek és a mesterséges intelligenciával kapcsolatos új fejlesztések mélyreható hatással lesznek arra, hogy az emberek hogyan lépnek kapcsolatba a kereséssel és hogyan jelennek meg az eredmények, de nincs helyettesítés, csak összefoglalás. Más szóval, az LLM modellek a keresés tetején vannak, nem pedig a keresés helyett."
Pujol kitart amellett, hogy egy LLM működtetése közel sem olyan költséges, mint a keresési infrastruktúra. "Egy valódi keresőmotor futtatása sokkal drágább, mint egy MI-modellé, még méretarányosan is" - mondta. "Ezt bizonyítja, hogy elég sok olyan cég van, amely LLM-et használ a kereső tetején (Perplexity, Arc, You, Kagi stb.). Megjegyzendő, hogy ezek a cégek talán mást állítanak, de mindegyik harmadik féltől származó keresési eredményekre támaszkodik. Nem sok olyan cég van, amely teljes értékű általános célú keresőmotorral rendelkezik, nevezetesen a Microsoft, a Google és a Brave. "Az LLM-eket nem lehet menet közben betanítani vagy finomhangolni, de a lekérdezés (következtetés) idején képesek beépíteni a támogató adatokat" - tette hozzá Pujol.
Arra a kérdésre, hogy mit tanult a Brave az MI bevezetése során, elmondta: "Jelenleg az egész iparág szomjazza a minőségi adatokat az MI-modellek képzéséhez, és egy független keresőmotor a kulcsfontosságú eszköze annak, hogy ezeket az adatokat harmadik feleknek szolgáltassuk. Eddig a Bing volt az egyetlen szereplő (a Google nem kínál API-t, legalábbis nem nyilvános hozzáféréssel), de drága, és szeszélyből változtatja az API-hozzáférési szabályait. Az új Brave Search API-nkkal az LLM-ek, fejlesztők és technológiai cégek rendelkezésére bocsáthatjuk az MI-alkalmazásaikhoz keresett adatokat. A Brave célja, hogy alternatívát nyújtson a big-tech számára; jellemzően mindig az embereket tartottuk szem előtt, de a kereső API-nk megjelenésével már a vállalkozásokat és intézményeket is ki tudjuk szolgálni."
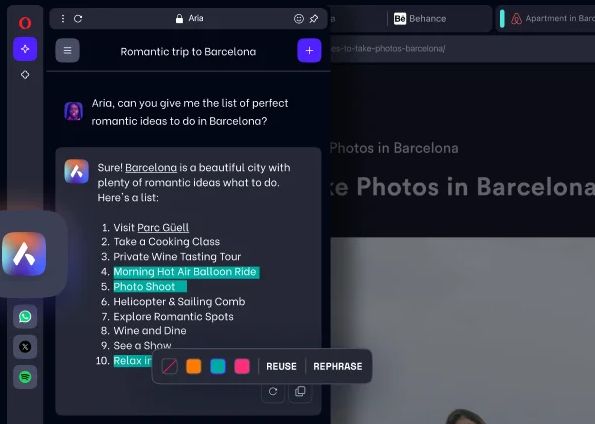
Az Opera tavaly júniusban jelentette be Opera One böngészőjét, amely tartalmazza a vállalat Aria MI asszisztensét. Jan Standal, az Opera alelnöke elmondta, hogy az Opera tervezi böngészőjének Blink és Chromium alapú iOS-verzióját most, hogy az Apple WebKit-követelménye megszűnik. Elmondása szerint jelenleg az Opera a Composer nevű saját MI backendjére támaszkodik, amely LLM-független, és lehetővé teszi különböző modellek, például az OpenAI modelljének csatlakoztatását. "Az Opera volt az első böngészőgyártó cég, amely az ingyenes Aria böngésző MI szolgáltatásával integrálta a mesterséges intelligenciát mind a PC-s, mind a mobil böngészőkbe" - mondta Standal.
"A szolgáltatás valós idejű keresési képességekkel, generatív szöveggel és a böngészővel való integrációval is rendelkezik a böngészőkérdéseken keresztül. Jelenlegi verziójában leginkább a felhasználók webes böngészés közbeni képességeinek bővítéseként képzelhető el. Véleményünk szerint az Aria nem versenyez a hagyományos kereséssel - ez egy kiegészítő szolgáltatás, amely lehetővé teszi, hogy az emberek összetettebb kérdéseket tegyenek fel a böngésző mesterséges intelligenciájának. A jövőben továbbfejlesztjük egy speciális böngésző MI-vé, amely a felhasználóknak lehetőséget biztosít a böngészési élményük javítására." - mondta Jan Standal.
Az Orion böngészőt és a Kagi Searchet gyártó Kagi az elmúlt években MI képességekkel egészítette ki termékeit, legutóbb a fizetős keresési szolgáltatásában. "Az MI-funkciók keresésbe történő bevezetésekor a fő szempontunk az volt, hogy a felhasználók produktívabbak legyenek, ugyanakkor egyértelművé tegyük, hogy az MI az emberi teljesítmény fokozására, nem pedig helyettesítésére szolgáló eszköz" - mondta Vladimir Prelovac alapító. "Ezért van az, hogy a Kagi összes ilyen funkciója jelenleg igény szerint aktiválódik. Például megkérhetjük a Kagit, hogy foglalja össze a keresési eredmények bármelyik oldalát, vagy akár az összes találatot. Vagy kérdéseket tehetünk fel a keresési eredményekben megjelenő bármely dokumentummal kapcsolatban". A Kagi nem méri az MI-válaszok hatékonyságát és felhasználását, a vállalat nem rendelkezik ilyen adatokkal. "A Kagi az adatvédelmet tiszteletben tartó keresőmotor, és nem követünk nyomon semmilyen felhasználói műveletet, beleértve a lekérdezéseket sem" - mondta. A Kagi azonban közzéteszi az általános használati statisztikákat: 20 515 fizető tagja van, akik több mint 347 000 lekérdezést tettek, és több mint 1200 napi Kagi Asszisztens-szálat használtak az elmúlt napokban az MI segítségével.
Arra a kérdésre, hogy a mesterséges intelligencia meg fogja-e változtatni a keresési üzletágat, Prelovac azt mondta, hogy számára egyértelmű, hogy igen. "Az MI a lekérdezések egy teljesen új, korábban nem létező terét tette lehetővé" - mondta. "Egy olyan egyszerűen hangzó lekérdezés, mint 'Melyik városnak van több lakosa, Berlin vagy Róma?' - ez korábban egy keresőmotorba beírva nem adott értelmes választ, ma már viszont az MI elég jó ahhoz, hogy árnyalt választ adjon. A (nagyon közeli) jövőben akár arra is meg lehet majd kérni a Kagit, hogy "rajzolj nekem egy diagramot a polgári repülés áldozatairól minden egyes évre vonatkozóan 1946 óta" - mondta. "Ez valóban lehetővé teszi a Google eredeti küldetését, a 'világ információinak rendszerezését', és lehet, hogy nem a Google lesz az, aki ezt teljesíteni fogja."
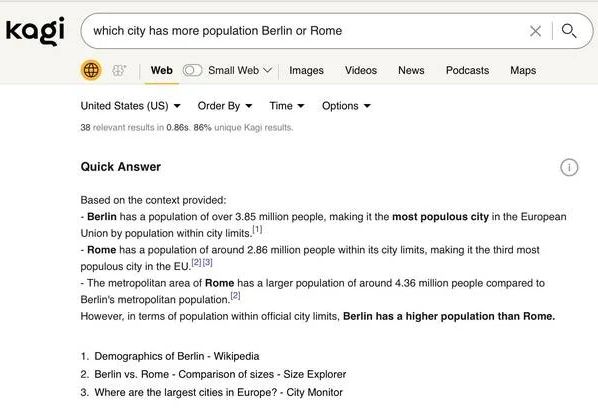
A keresők eddig képtelenek voltak egy egyszerű kérdést megválaszolni
Prelovac szerint ahhoz, hogy a kiadók részt vehessenek ebben a mesterséges intelligencia-orientált keresésben, a keresőmotoroknak mindig eredeti forrásokat kellene idézniük, ahogyan azt a Kagi is teszi, és a keresőmotorok nyereségéből a kiadói linkek megjelenésével arányosan részesedést kellene biztosítaniuk. "Ez összehangolná az összes ösztönzőt, és pozitív visszacsatolási hurkot hozna létre" - mondta. Prelovac szerint vannak olyan kontextusok, amelyekben a keresés jobban működik, mint a mesterséges intelligencia, és fordítva, ezért arra számít, hogy mindkettő még sokáig szerepet fog játszani. "A legtöbb lekérdezés még mindig túl lassú a mesterséges intelligenciával" - mondta. "Például a 'Starbucks a közelemben' vagy egy film keresése. Ezt összehasonlítva azzal, hogy öt másodpercet várok arra, hogy az MI kiadjon egy szövegfalat, amely vagy tartalmazza, vagy nem tartalmazza a kívánt választ, nyilvánvalóan szuboptimális."
Az eddig tárgyalt eszközök azonban az általános fogyasztói használatra összpontosítanak. Speciálisabb kontextusokban a mesterséges intelligencia-modelleknek a nyilatkozatban említett hiányosságait, például a pontatlanságot és a forrásadatok hiányát nem lehet olyan könnyen figyelmen kívül hagyni. Dr. William Hersh, az Oregoni Egészségügyi és Tudományos Egyetem Orvosi Karának orvosi informatikai és klinikai epidemiológiai tanszékének professzora tanulmányt írt a kérdésről, és szerinte ugyan az MI segítheti az információkeresést, de nem helyettesítheti azt. "Gyakran fontos, amikor keresünk, hogy ismerjük az információ forrását, és hogy mi támasztja alá azt. Egyes orvosi kérdésekre a mesterséges intelligencia adhat valamilyen választ, de az orvostudományban és a tudományos életben nagy a tétje annak, hogy helyesen válaszoljunk".
"Amikor információt keresek, akár tanításhoz, akár klinikai alkalmazáshoz, fontos számomra, hogy tudjam, ki írta az adott dolgot és milyen bizonyítékok támasztják azt alá" - magyarázta Hersh. "Mivel egy adott témáról számos tanulmány készülhet, látni akarom az eredeti forrásokat, hogy saját szintézist készíthessek és értékelhessem a tanulmányok mondanivalóját. Hasznos lehet egy szakirodalmi anyag MI-összefoglalása, de sokszor előfordul, hogy a forrásadatokat is be akarjuk mutatni, hogy saját döntést hozhassunk." A segítő mesterséges intelligencia hasznos lehet az ötletek megfogalmazásában és az információk értelmezésének segítésében, mondta Hersh, de a klinikai vagy oktatási környezetben fontos döntéseket hozó emberek számára, amelyek konkrét információkon alapulnak, "látni, hogy honnan származik az információ, ugyanolyan fontos, mint annak valamilyen MI szintézise".
Hersh megjegyzi, hogy az internet kezdete óta aggályok merültek fel az információ minőségével kapcsolatban. Kezdetben a Google kereső úgy segített, hogy az oldalakat a relevancia alapján rangsorolta, ami a minőség helyettesítője lett. "Ennek ellenére az információminőséggel kapcsolatos háborút valószínűleg elvesztettük, különösen a közösségi média megjelenésével, valamint a dezinformáció lekérdezésének manipulálására szolgáló módszerekkel." Arra a kérdésre, hogy szerinte a keresés alternatívái iránti érdeklődés részben azzal függ-e össze, hogy a szennyezett információs környezetben egyre nehezebb jó válaszokat kapni, Hersh azt mondta: "Igen, nagyon is; az internetet elárasztották a dezinformációk, és a Google és más keresőmotorok esetében kihívást jelent a jót a rossztól elválasztani. Egy másik ok, amiért a forrásinformáció olyan kulcsfontosságú: az orvosi szakirodalom és annak a PubMed-en keresztüli keresése sokkal jobb, bár még mindig vannak hiányosságai".
Ha a Google Bardot megkérdezzük milyen lesz a keresés jövője, egy összefoglalót kapunk azokról a trendekről, amelyek azt sugallják, hogy a keresés többről szól, mint kulcsszavak keresése egy dokumentumindexben. Megemlíti a személyre szabást és a más szolgáltatásokkal való integrációkat, de kitér még az olyan etikai megfontolásokra is, mint a magánélet védelme, az elfogultság, a pontatlanság és a dezinformáció. A Bard azonban nem foglalkozik a gazdaságossággal, ami kulcsfontosságú szempont. A Google keresési üzletágának 2023. harmadik negyedévi bevétele elérte a 44 milliárd dollárt, és a riválisok szívesen lecsapnának ennek a pénznek egy részére.
Ha a mesterséges intelligencia felborítja a keresőhirdetési üzletágat - ahogy sokak szerint már most is teszi - annak nemcsak a Google és a konkurens cégek, hanem az ökoszisztémában részt vevő összes kiadó számára is következményei lesznek. A híroldalaknak nincs pénzügyi ösztönzőjük arra, hogy engedélyezzék a mesterséges intelligenciával működő keresőszolgáltatásokat abban, hogy feltérképezzék és összefoglalják munkájukat, ha az internetfelhasználók csak egy összefoglaló oldalt látnak, de soha nem látogatnak el a kiadó oldalára, és nem generálnak hirdetési megjelenéseket.
Az alul megjelenő linkekre senki nem fog kattintani, ha az MI választ ad
A mesterséges intelligencia keresési szolgáltatásokba való beépítése nemcsak a Google és a kiadók számára jár gazdasági következményekkel, hanem a versenytársak számára is, akiknek viselniük kell a gépi tanulási modellek fejlesztésének és bevezetésének költségeit. A Microsoft GitHub Copilotja a hírek szerint havonta akár 80 dollárt is veszít felhasználónként. Mind a Microsoft, mind a Google 30 dolláros felárat tervez felszámítani az Office 365 és a Google Workspace MI-funkcióiért, az OpenAI API-ját alkalmazó fejlesztőknek pedig fizetniük kell a kiváltságért. Ez nem teljesen meglepő, tekintve, hogy az Alphabet elnöke, John Hennessy azt nyilatkozta, hogy "a nagy nyelvi modellként ismert MI-vel való keresés 10-szer annyiba kerül, mint egy hagyományos kulcsszavas keresés, bár a finomhangolás gyorsan segít csökkenteni a kiadásokat". Ezt egy másik tanulmány is visszhangozza ("The growing energy footprint of artificial intelligence" - A mesterséges intelligencia növekvő energiaigénye), amelynek becslése szerint egy hagyományos Google-keresés 0,3 Wh áramot fogyaszt, míg egy mesterséges intelligenciával támogatott 3,0 Wh-t.
Az etikai kérdések felsorolásában a Bard figyelmen kívül hagyja a lényeget: hogy a tartalmakat fizetés vagy beleegyezés nélkül rögzítik, majd eladják az embereknek, miközben a munkájukat árucikké teszik. De ebben a tekintetben a Bard olyan, mint mindazok, akik túl hasznosnak találják a mesterséges intelligenciát ahhoz, hogy erkölcsi megfontolások miatt elutasítsák. Az MI-alapú keresés körüli izgalom nagy része annak köszönhető, hogy a technológiai ipar (és a média) arra összpontosít, hogy mi lesz a következő lépés. A Google évtizedek óta a keresés domináns hatalma, és az emberek éhesek a változásra, különösen mivel az elmúlt években a keresés minősége nagyot csökkent, és ezt a tendenciát ironikus módon tovább súlyosbítja a generatív MI-tartalmak elterjedése.
A Microsoft 2023 februárjában azt mondta, hogy "újra feltalálja a keresést egy új, MI-alapú Microsoft Bing és Edge segítségével". A bejelentés elindította a találgatásokat a Google Kereső utódjáról, vagy legalábbis a rendszerváltás katalizátoráról. Egy év elteltével megállapíthatjuk, hogy az MI nem segített a Bingnek abban, hogy piaci részesedést szerezzen a Google-től. Ennek ellenére a kereső- és böngészőüzletág kisebb riválisai bíznak az MI-ben - akár a Google dominanciájának megtörése, akár a Google által le nem fedett piac egy részének megszerzése, akár a keresést kiegészítő, márka-megkülönböztető funkciók hozzáadása, akár a befektetők lenyűgözése miatt.
A Browser Company nemrég indította el az Arc Searchet. Ez egy iOS-re készült mobil böngésző, amely beépített reklámblokkolóval van ellátva. A böngésző a készülék alapértelmezett keresőmotorján (ami valószínűleg a Google) keresztül keres, majd a lekérdezést átadja a mesterséges intelligencia modelljének, hogy az egy összefoglaló weboldalt hozzon létre a remélhetőleg releváns részletekkel. A Browse for Me összefoglaló opció lassan, több másodperc alatt hoz létre egy kellemesen olvasható reklámmentes weboldalt, amely több forrásból származó válogatott összefoglalót tartalmaz. Az oldal ugyan tartalmaz linkeket ezekre az oldalakra, de nem látható, hogy melyik idézett adatpont melyik oldalról származik.
A Brave Software novemberben mutatta be a Brave böngészőjéhez a Leo nevű adatvédelmet biztosító MI-asszisztenst, amelyet nemrég integráltak a Mixtral 8x7B nevű nyílt forráskódú nagy nyelvi modellel. A Brave a keresési találati oldalának összefoglaló szakaszának létrehozásához használja a mesterséges intelligenciát, amely (többnyire) a saját keresési indexéből származik, és vagy hirdetésekkel vagy 3 dollár/hó Premium előfizetési díjjal támogatott. Josep M. Pujol, a Brave keresésért felelős vezetője szerint az LLM nem helyettesíti a keresést. "Az LLM-alapú keresés előfeltétele, hogy legyen egy mögöttes keresőmotor, akár saját tulajdonú és működtetésű, akár harmadik féltől származó API-n keresztül" - mondta Pujol. "De index nélkül (vagy indexhez való hozzáférés nélkül) nem lehet keresés. Az LLM-ek és a mesterséges intelligenciával kapcsolatos új fejlesztések mélyreható hatással lesznek arra, hogy az emberek hogyan lépnek kapcsolatba a kereséssel és hogyan jelennek meg az eredmények, de nincs helyettesítés, csak összefoglalás. Más szóval, az LLM modellek a keresés tetején vannak, nem pedig a keresés helyett."
Pujol kitart amellett, hogy egy LLM működtetése közel sem olyan költséges, mint a keresési infrastruktúra. "Egy valódi keresőmotor futtatása sokkal drágább, mint egy MI-modellé, még méretarányosan is" - mondta. "Ezt bizonyítja, hogy elég sok olyan cég van, amely LLM-et használ a kereső tetején (Perplexity, Arc, You, Kagi stb.). Megjegyzendő, hogy ezek a cégek talán mást állítanak, de mindegyik harmadik féltől származó keresési eredményekre támaszkodik. Nem sok olyan cég van, amely teljes értékű általános célú keresőmotorral rendelkezik, nevezetesen a Microsoft, a Google és a Brave. "Az LLM-eket nem lehet menet közben betanítani vagy finomhangolni, de a lekérdezés (következtetés) idején képesek beépíteni a támogató adatokat" - tette hozzá Pujol.
Arra a kérdésre, hogy mit tanult a Brave az MI bevezetése során, elmondta: "Jelenleg az egész iparág szomjazza a minőségi adatokat az MI-modellek képzéséhez, és egy független keresőmotor a kulcsfontosságú eszköze annak, hogy ezeket az adatokat harmadik feleknek szolgáltassuk. Eddig a Bing volt az egyetlen szereplő (a Google nem kínál API-t, legalábbis nem nyilvános hozzáféréssel), de drága, és szeszélyből változtatja az API-hozzáférési szabályait. Az új Brave Search API-nkkal az LLM-ek, fejlesztők és technológiai cégek rendelkezésére bocsáthatjuk az MI-alkalmazásaikhoz keresett adatokat. A Brave célja, hogy alternatívát nyújtson a big-tech számára; jellemzően mindig az embereket tartottuk szem előtt, de a kereső API-nk megjelenésével már a vállalkozásokat és intézményeket is ki tudjuk szolgálni."
Az Opera tavaly júniusban jelentette be Opera One böngészőjét, amely tartalmazza a vállalat Aria MI asszisztensét. Jan Standal, az Opera alelnöke elmondta, hogy az Opera tervezi böngészőjének Blink és Chromium alapú iOS-verzióját most, hogy az Apple WebKit-követelménye megszűnik. Elmondása szerint jelenleg az Opera a Composer nevű saját MI backendjére támaszkodik, amely LLM-független, és lehetővé teszi különböző modellek, például az OpenAI modelljének csatlakoztatását. "Az Opera volt az első böngészőgyártó cég, amely az ingyenes Aria böngésző MI szolgáltatásával integrálta a mesterséges intelligenciát mind a PC-s, mind a mobil böngészőkbe" - mondta Standal.
"A szolgáltatás valós idejű keresési képességekkel, generatív szöveggel és a böngészővel való integrációval is rendelkezik a böngészőkérdéseken keresztül. Jelenlegi verziójában leginkább a felhasználók webes böngészés közbeni képességeinek bővítéseként képzelhető el. Véleményünk szerint az Aria nem versenyez a hagyományos kereséssel - ez egy kiegészítő szolgáltatás, amely lehetővé teszi, hogy az emberek összetettebb kérdéseket tegyenek fel a böngésző mesterséges intelligenciájának. A jövőben továbbfejlesztjük egy speciális böngésző MI-vé, amely a felhasználóknak lehetőséget biztosít a böngészési élményük javítására." - mondta Jan Standal.
Az Orion böngészőt és a Kagi Searchet gyártó Kagi az elmúlt években MI képességekkel egészítette ki termékeit, legutóbb a fizetős keresési szolgáltatásában. "Az MI-funkciók keresésbe történő bevezetésekor a fő szempontunk az volt, hogy a felhasználók produktívabbak legyenek, ugyanakkor egyértelművé tegyük, hogy az MI az emberi teljesítmény fokozására, nem pedig helyettesítésére szolgáló eszköz" - mondta Vladimir Prelovac alapító. "Ezért van az, hogy a Kagi összes ilyen funkciója jelenleg igény szerint aktiválódik. Például megkérhetjük a Kagit, hogy foglalja össze a keresési eredmények bármelyik oldalát, vagy akár az összes találatot. Vagy kérdéseket tehetünk fel a keresési eredményekben megjelenő bármely dokumentummal kapcsolatban". A Kagi nem méri az MI-válaszok hatékonyságát és felhasználását, a vállalat nem rendelkezik ilyen adatokkal. "A Kagi az adatvédelmet tiszteletben tartó keresőmotor, és nem követünk nyomon semmilyen felhasználói műveletet, beleértve a lekérdezéseket sem" - mondta. A Kagi azonban közzéteszi az általános használati statisztikákat: 20 515 fizető tagja van, akik több mint 347 000 lekérdezést tettek, és több mint 1200 napi Kagi Asszisztens-szálat használtak az elmúlt napokban az MI segítségével.
Arra a kérdésre, hogy a mesterséges intelligencia meg fogja-e változtatni a keresési üzletágat, Prelovac azt mondta, hogy számára egyértelmű, hogy igen. "Az MI a lekérdezések egy teljesen új, korábban nem létező terét tette lehetővé" - mondta. "Egy olyan egyszerűen hangzó lekérdezés, mint 'Melyik városnak van több lakosa, Berlin vagy Róma?' - ez korábban egy keresőmotorba beírva nem adott értelmes választ, ma már viszont az MI elég jó ahhoz, hogy árnyalt választ adjon. A (nagyon közeli) jövőben akár arra is meg lehet majd kérni a Kagit, hogy "rajzolj nekem egy diagramot a polgári repülés áldozatairól minden egyes évre vonatkozóan 1946 óta" - mondta. "Ez valóban lehetővé teszi a Google eredeti küldetését, a 'világ információinak rendszerezését', és lehet, hogy nem a Google lesz az, aki ezt teljesíteni fogja."
A keresők eddig képtelenek voltak egy egyszerű kérdést megválaszolni
Prelovac szerint ahhoz, hogy a kiadók részt vehessenek ebben a mesterséges intelligencia-orientált keresésben, a keresőmotoroknak mindig eredeti forrásokat kellene idézniük, ahogyan azt a Kagi is teszi, és a keresőmotorok nyereségéből a kiadói linkek megjelenésével arányosan részesedést kellene biztosítaniuk. "Ez összehangolná az összes ösztönzőt, és pozitív visszacsatolási hurkot hozna létre" - mondta. Prelovac szerint vannak olyan kontextusok, amelyekben a keresés jobban működik, mint a mesterséges intelligencia, és fordítva, ezért arra számít, hogy mindkettő még sokáig szerepet fog játszani. "A legtöbb lekérdezés még mindig túl lassú a mesterséges intelligenciával" - mondta. "Például a 'Starbucks a közelemben' vagy egy film keresése. Ezt összehasonlítva azzal, hogy öt másodpercet várok arra, hogy az MI kiadjon egy szövegfalat, amely vagy tartalmazza, vagy nem tartalmazza a kívánt választ, nyilvánvalóan szuboptimális."
Az eddig tárgyalt eszközök azonban az általános fogyasztói használatra összpontosítanak. Speciálisabb kontextusokban a mesterséges intelligencia-modelleknek a nyilatkozatban említett hiányosságait, például a pontatlanságot és a forrásadatok hiányát nem lehet olyan könnyen figyelmen kívül hagyni. Dr. William Hersh, az Oregoni Egészségügyi és Tudományos Egyetem Orvosi Karának orvosi informatikai és klinikai epidemiológiai tanszékének professzora tanulmányt írt a kérdésről, és szerinte ugyan az MI segítheti az információkeresést, de nem helyettesítheti azt. "Gyakran fontos, amikor keresünk, hogy ismerjük az információ forrását, és hogy mi támasztja alá azt. Egyes orvosi kérdésekre a mesterséges intelligencia adhat valamilyen választ, de az orvostudományban és a tudományos életben nagy a tétje annak, hogy helyesen válaszoljunk".
"Amikor információt keresek, akár tanításhoz, akár klinikai alkalmazáshoz, fontos számomra, hogy tudjam, ki írta az adott dolgot és milyen bizonyítékok támasztják azt alá" - magyarázta Hersh. "Mivel egy adott témáról számos tanulmány készülhet, látni akarom az eredeti forrásokat, hogy saját szintézist készíthessek és értékelhessem a tanulmányok mondanivalóját. Hasznos lehet egy szakirodalmi anyag MI-összefoglalása, de sokszor előfordul, hogy a forrásadatokat is be akarjuk mutatni, hogy saját döntést hozhassunk." A segítő mesterséges intelligencia hasznos lehet az ötletek megfogalmazásában és az információk értelmezésének segítésében, mondta Hersh, de a klinikai vagy oktatási környezetben fontos döntéseket hozó emberek számára, amelyek konkrét információkon alapulnak, "látni, hogy honnan származik az információ, ugyanolyan fontos, mint annak valamilyen MI szintézise".
Hersh megjegyzi, hogy az internet kezdete óta aggályok merültek fel az információ minőségével kapcsolatban. Kezdetben a Google kereső úgy segített, hogy az oldalakat a relevancia alapján rangsorolta, ami a minőség helyettesítője lett. "Ennek ellenére az információminőséggel kapcsolatos háborút valószínűleg elvesztettük, különösen a közösségi média megjelenésével, valamint a dezinformáció lekérdezésének manipulálására szolgáló módszerekkel." Arra a kérdésre, hogy szerinte a keresés alternatívái iránti érdeklődés részben azzal függ-e össze, hogy a szennyezett információs környezetben egyre nehezebb jó válaszokat kapni, Hersh azt mondta: "Igen, nagyon is; az internetet elárasztották a dezinformációk, és a Google és más keresőmotorok esetében kihívást jelent a jót a rossztól elválasztani. Egy másik ok, amiért a forrásinformáció olyan kulcsfontosságú: az orvosi szakirodalom és annak a PubMed-en keresztüli keresése sokkal jobb, bár még mindig vannak hiányosságai".