SG.hu·
Egymilliárd objektumot ismer fel a Google Lens
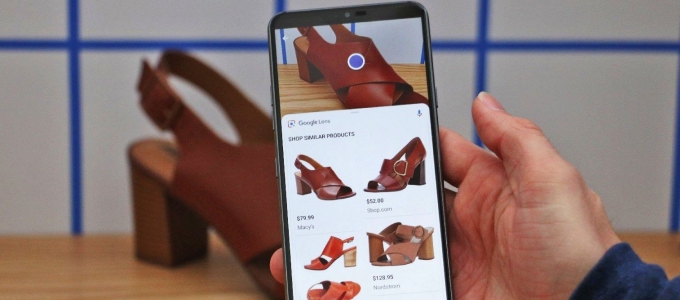
Komoly fejlődésen ment keresztül a képfelismerő program: hiba nélkül megkülönbözteti a termékcímkéken az o és a 0 karaktereket.
 A Google Lens nevű képfelismerő program alig egy év alatt eljutott arra a szintre, hogy immár egymilliárd tárgyat képes felismerni. Körülbelül egy esztendővel ezelőtt ez a szám még csupán 250 millió volt. A fejlődés az alkalmazás javított olvasási képességeinek köszönhető - minderről blogbejegyzésében Aparna Chennapragada, a Google Lensért és kiterjesztett valóság rendszerekért felelős alelnöke számolt be.
A Google Lens nevű képfelismerő program alig egy év alatt eljutott arra a szintre, hogy immár egymilliárd tárgyat képes felismerni. Körülbelül egy esztendővel ezelőtt ez a szám még csupán 250 millió volt. A fejlődés az alkalmazás javított olvasási képességeinek köszönhető - minderről blogbejegyzésében Aparna Chennapragada, a Google Lensért és kiterjesztett valóság rendszerekért felelős alelnöke számolt be.
A menedzser azt írta, hogy úgy sikerült javítani a Lens olvasási képességein, hogy a társaság ötvözött egy felhasználók által meghatározott optikai karakterfelismerő motort a saját beszédtapasztalataival. Az utóbbiak a keresőjéből és a Knowledge Graph rendszeréből származtak. Az optikai karakterfelismerő motornak és a tanulásnak köszönhetően a Lens nagyon jó lett a termékcímkék és más szövegek elolvasásában, mindez pedig segít a több mint egymilliárd termék azonosításában. Ahhoz, hogy a Lens különbséget tudjon tenni egy o betű és a 0 között, a Google keresőjének helyesírási korrektúramodelljére támaszkodik.
Chennapragada azt közölte, ha a számítógépek elkezdenek úgy látni, ahogy az emberek, akkor a kamerák komoly teljesítményű és intuitív interfészek lesznek a felhasználók körülvevő világ számára. Úgy véli, létrehozható lenne egy mesterséges intelligencia kereső, amely a válaszokat pontosan ott találja meg, ahol a kérdések vannak; a keresett termékek "előretolakodnának" a polcokon, valamint egy idegen városban minden felbukkanó szó azonnal automatikusan megjelenne más nyelven is. Az emberek továbbra is élhetik majd az életüket, de sokkal többet fognak tudni a körülöttük zajló dolgokról.
A Google Lens nevű képfelismerő program alig egy év alatt eljutott arra a szintre, hogy immár egymilliárd tárgyat képes felismerni. Körülbelül egy esztendővel ezelőtt ez a szám még csupán 250 millió volt. A fejlődés az alkalmazás javított olvasási képességeinek köszönhető - minderről blogbejegyzésében Aparna Chennapragada, a Google Lensért és kiterjesztett valóság rendszerekért felelős alelnöke számolt be.A menedzser azt írta, hogy úgy sikerült javítani a Lens olvasási képességein, hogy a társaság ötvözött egy felhasználók által meghatározott optikai karakterfelismerő motort a saját beszédtapasztalataival. Az utóbbiak a keresőjéből és a Knowledge Graph rendszeréből származtak. Az optikai karakterfelismerő motornak és a tanulásnak köszönhetően a Lens nagyon jó lett a termékcímkék és más szövegek elolvasásában, mindez pedig segít a több mint egymilliárd termék azonosításában. Ahhoz, hogy a Lens különbséget tudjon tenni egy o betű és a 0 között, a Google keresőjének helyesírási korrektúramodelljére támaszkodik.
Chennapragada azt közölte, ha a számítógépek elkezdenek úgy látni, ahogy az emberek, akkor a kamerák komoly teljesítményű és intuitív interfészek lesznek a felhasználók körülvevő világ számára. Úgy véli, létrehozható lenne egy mesterséges intelligencia kereső, amely a válaszokat pontosan ott találja meg, ahol a kérdések vannak; a keresett termékek "előretolakodnának" a polcokon, valamint egy idegen városban minden felbukkanó szó azonnal automatikusan megjelenne más nyelven is. Az emberek továbbra is élhetik majd az életüket, de sokkal többet fognak tudni a körülöttük zajló dolgokról.