Alex
Szuperszámítógéppel elemzik a Wikipédiát
A teljes angol nyelvű Wikipédiát feltöltötték egy szuperszámítógép memóriájába, hogy megalkossák a történelmi térképét és feltárják a szövegtartalmakat mind térben, mind időben.
Az SGI összefogott az Illinois Egyetem munkatársával, Kalev H. Leetaruval, hogy a világon elsőként elkészítsék a Wikipédia angol nyelvű változatának történelmi térképét. A cég szuperszámítógépébe feltöltötték a teljes adatbázist, hogy bemutassák hogyan látja a Wikipedia az elmúlt kétszáz év történelmét. A hivatkozásokhoz hozzákapcsolták a helyszínt, az évet és a pozitív vagy negatív hangulatot. A feltöltést követően ez a rendkívül nagy adathalmaz teljes szöveg-geokódoláson és dátum-kódoláson esett át, olyan algoritmusok használatának segítségével, amelyek minden megemlített helyszínt és dátumot azonosítottak a Wikipédia összes bejegyzésének szövegében.
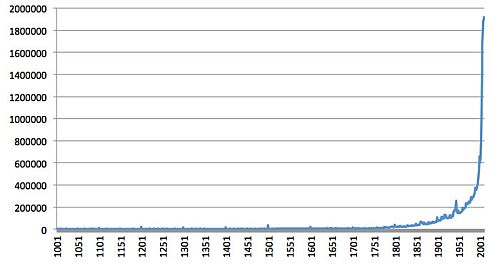
A Wikipédia évekre vonatkozó bejegyzései. Jól látható kiugrás van a századfordulóknál és a világháborúknál
Több, mint 80 millió helyszínt és 42 millió dátumot rögzítettek i.e.1000-től 2012-ig. Átlagosan 19 helyszín és 11 dátum szerepelt egy-egy cikkben (minden 44 szó helyszínre, és minden 75 szó dátumra vonatkozott). A dátumok és helyszínek közti kapcsolódásokat egy masszív adathálóra vitték fel, amely a Wikipédia történelemről alkotott nézeteit tükrözte. Ennek az eszköznek a segítségével Leetaru majdhogynem valós idejű elemzést végezhetett a feltöltött teljes adatbázisban abból a célból, hogy vizuális térképet készítsen az idő- és helyadatok folyamáról, láttatva nem csak a történelmi események kibontakozását, hanem a világ általános hangulatát is az elmúlt ezer évben, és interaktív módon vizsgáljon meg számos elméletet és kutatási kérdést alig egy napi munkával.
Bár korábban már több projekt keretében is feltérképezték az online lexikon cikkeit kézileg, egy szerkesztő által hozzárendelt metaadatok segítségével, ezek a korábbi kísérletek a Wikipédia helyszínekre vonatkozó adatainak csak egy töredékét tudták feldolgozni. A jelenlegi projekt keretében azonban dekódolták a cikkek tartalmát, azonosítva a négy millió oldalon szereplő összes helyszínt és dátumot, és a köztük fennálló kapcsolatokat.
A hely, az idő és az érzelmek összekapcsolva (a zöld a pozitív, a piros a negatív)
"Ezzel az elemzéssel lehetővé válik az emberiség számára, hogy hátralépjen egy lépést, azaz elvonatkoztasson az egyes cikkek és szövegek egyedi vonásaitól, és az egyes lapokon szereplő elszigetelt információk, azaz a "fa" helyett az "erdőt" lássa: azt a hatalmas tudásanyagot, amely a Wikipédiában felhalmozódott. Figyelemmel kísérhetjük, hogyan fejlődött az emberi tudás egyik legnagyobb tárháza, és láthatunk olyan dolgokat, amiket még soha ezelőtt: például az általános hangulatot egy adott időben és helyen, vagy hogy hol vannak még tudásunkban vakfoltok" - magyarázta Franz Aman, az SGI értékesítési és stratégiai igazgatója. "A Google Earth alkalmazást azért szeretjük, mert kisebbre véve a felbontást nagyobb léptékű képet kaphatunk. Az SGI UV 2 segítségével ugyanezt megtehetjük az átfogó adatokkal, hogy azok alapján átfogó képet kapjunk."
Az elemzés azt mutatja, hogy a Wikipédia négy fejlődési szakaszon ment keresztül a történelmi események rögzítését illetően: 1001-1500 (Középkor), 1501-1729 (Korai modernkor), 1730-2003 (A Felvilágosodás kora), 2004-2011 (a Wikipédia Éra) és mostani fejlődése a történelmi események alaposabb lefedését célozza ahelyett, hogy a jelen történéseit dokumentálná bővebben. A lexikon általános hangvétele, hangulata az egyes évek krónikájának rögzítésében szorosan követi a főbb nemzetközi eseményeket. Az elmúlt 1000 évben a legnegatívabb hangulatú az Amerikai Polgárháború, majd a II. Világháború idején volt. Az elemzés azt is kimutatja, hogy az ún. szerzői jogi szakadék, amely miatt a 20. századra vonatkozó digitalizált nyomtatott szövegek nagy része nem követhető, nem jelent problémát a Wikipédia esetében, ahol folyamatos, exponenciális növekedés figyelhető meg az 1924-es évtől kezdve a mai napig rögzített cikkek, bejegyzések tekintetében.
"A Wikipédia egyirányú kapcsolódásai illetve esetlegesen a kapcsolódások hiánya, az infódobozok egyenetlen eloszlása egyaránt azt mutatja, hogy az olyan gyűjtemények, mint a Wikipédia esetében a metaadatokon alapuló adatbányászatnak megvannak a maga korlátai" - fejtette ki Leetaru. "A szuperszámítógép nagy megosztott memóriája révén a teljes adatkészletre vonatkozó kérdéseket tehettem fel gyakorlatilag valós időben. Lehetővé vált, hogy néhány soros kódot írva a teljes adathalmazon átfuttassak bármilyen kérdést, ami csak az eszembe jut. Erre egy horizontális skálázású megközelítéssel nem lett volna esélyem. Hasonlatképpen a számítógépes szövegszerkesztő program és az írógép közti hatalmas funkcionalitásbeli különbséget tudnám felhozni; a szuperszámítógépet használva teljesen máshogy végezhetem a kutatást és a kimenetekre összpontosíthatok az algoritmusok helyett."
Az SGI összefogott az Illinois Egyetem munkatársával, Kalev H. Leetaruval, hogy a világon elsőként elkészítsék a Wikipédia angol nyelvű változatának történelmi térképét. A cég szuperszámítógépébe feltöltötték a teljes adatbázist, hogy bemutassák hogyan látja a Wikipedia az elmúlt kétszáz év történelmét. A hivatkozásokhoz hozzákapcsolták a helyszínt, az évet és a pozitív vagy negatív hangulatot. A feltöltést követően ez a rendkívül nagy adathalmaz teljes szöveg-geokódoláson és dátum-kódoláson esett át, olyan algoritmusok használatának segítségével, amelyek minden megemlített helyszínt és dátumot azonosítottak a Wikipédia összes bejegyzésének szövegében.
A Wikipédia évekre vonatkozó bejegyzései. Jól látható kiugrás van a századfordulóknál és a világháborúknál
Több, mint 80 millió helyszínt és 42 millió dátumot rögzítettek i.e.1000-től 2012-ig. Átlagosan 19 helyszín és 11 dátum szerepelt egy-egy cikkben (minden 44 szó helyszínre, és minden 75 szó dátumra vonatkozott). A dátumok és helyszínek közti kapcsolódásokat egy masszív adathálóra vitték fel, amely a Wikipédia történelemről alkotott nézeteit tükrözte. Ennek az eszköznek a segítségével Leetaru majdhogynem valós idejű elemzést végezhetett a feltöltött teljes adatbázisban abból a célból, hogy vizuális térképet készítsen az idő- és helyadatok folyamáról, láttatva nem csak a történelmi események kibontakozását, hanem a világ általános hangulatát is az elmúlt ezer évben, és interaktív módon vizsgáljon meg számos elméletet és kutatási kérdést alig egy napi munkával.
Bár korábban már több projekt keretében is feltérképezték az online lexikon cikkeit kézileg, egy szerkesztő által hozzárendelt metaadatok segítségével, ezek a korábbi kísérletek a Wikipédia helyszínekre vonatkozó adatainak csak egy töredékét tudták feldolgozni. A jelenlegi projekt keretében azonban dekódolták a cikkek tartalmát, azonosítva a négy millió oldalon szereplő összes helyszínt és dátumot, és a köztük fennálló kapcsolatokat.
A hely, az idő és az érzelmek összekapcsolva (a zöld a pozitív, a piros a negatív)
"Ezzel az elemzéssel lehetővé válik az emberiség számára, hogy hátralépjen egy lépést, azaz elvonatkoztasson az egyes cikkek és szövegek egyedi vonásaitól, és az egyes lapokon szereplő elszigetelt információk, azaz a "fa" helyett az "erdőt" lássa: azt a hatalmas tudásanyagot, amely a Wikipédiában felhalmozódott. Figyelemmel kísérhetjük, hogyan fejlődött az emberi tudás egyik legnagyobb tárháza, és láthatunk olyan dolgokat, amiket még soha ezelőtt: például az általános hangulatot egy adott időben és helyen, vagy hogy hol vannak még tudásunkban vakfoltok" - magyarázta Franz Aman, az SGI értékesítési és stratégiai igazgatója. "A Google Earth alkalmazást azért szeretjük, mert kisebbre véve a felbontást nagyobb léptékű képet kaphatunk. Az SGI UV 2 segítségével ugyanezt megtehetjük az átfogó adatokkal, hogy azok alapján átfogó képet kapjunk."
Az elemzés azt mutatja, hogy a Wikipédia négy fejlődési szakaszon ment keresztül a történelmi események rögzítését illetően: 1001-1500 (Középkor), 1501-1729 (Korai modernkor), 1730-2003 (A Felvilágosodás kora), 2004-2011 (a Wikipédia Éra) és mostani fejlődése a történelmi események alaposabb lefedését célozza ahelyett, hogy a jelen történéseit dokumentálná bővebben. A lexikon általános hangvétele, hangulata az egyes évek krónikájának rögzítésében szorosan követi a főbb nemzetközi eseményeket. Az elmúlt 1000 évben a legnegatívabb hangulatú az Amerikai Polgárháború, majd a II. Világháború idején volt. Az elemzés azt is kimutatja, hogy az ún. szerzői jogi szakadék, amely miatt a 20. századra vonatkozó digitalizált nyomtatott szövegek nagy része nem követhető, nem jelent problémát a Wikipédia esetében, ahol folyamatos, exponenciális növekedés figyelhető meg az 1924-es évtől kezdve a mai napig rögzített cikkek, bejegyzések tekintetében.
"A Wikipédia egyirányú kapcsolódásai illetve esetlegesen a kapcsolódások hiánya, az infódobozok egyenetlen eloszlása egyaránt azt mutatja, hogy az olyan gyűjtemények, mint a Wikipédia esetében a metaadatokon alapuló adatbányászatnak megvannak a maga korlátai" - fejtette ki Leetaru. "A szuperszámítógép nagy megosztott memóriája révén a teljes adatkészletre vonatkozó kérdéseket tehettem fel gyakorlatilag valós időben. Lehetővé vált, hogy néhány soros kódot írva a teljes adathalmazon átfuttassak bármilyen kérdést, ami csak az eszembe jut. Erre egy horizontális skálázású megközelítéssel nem lett volna esélyem. Hasonlatképpen a számítógépes szövegszerkesztő program és az írógép közti hatalmas funkcionalitásbeli különbséget tudnám felhozni; a szuperszámítógépet használva teljesen máshogy végezhetem a kutatást és a kimenetekre összpontosíthatok az algoritmusok helyett."